

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 웹 스크랩핑
- 내일배움카드
- 스파르타
- harkerrank
- 파이썬 머신러닝 완벽 가이드
- TiL
- hackerrank
- 스파르타 코딩
- 파이썬
- Cluster
- 내일배움캠프
- 중회귀모형
- 실전 데이터 분석 프로젝트
- wil
- 스파르타코딩
- 파이썬 완벽 가이드
- 미세먼지
- 파이썬 머신러닝 완벽가이드
- 파이썬 철저 입문
- 프로젝트
- 텍스트 분석
- SQL
- 오블완
- 프로그래머스
- 파이썬 철저입문
- 티스토리챌린지
- MySQL
- 내일배움
- 회귀분석
- R
- Today
- Total
OkBublewrap
[통계 101 x 데이터 분석] 통계분석과 관련된 그 밖의 방법 본문
주성분 분석
변수의 차원
차원이 높다고 하면 정보량이 많으니 얼핏 좋은 것처럼 생각되지만, 실은 쓸데없이 많기만 한 상황이 종종 발생합니다.
상관이 있는 변수의 수를 줄이는 것이, 차원축소라고 합니다.
변수의 수를 줄이는 이유
- 고차원 데이터 해석의 어려움
- 저차원 데이터는 시각화 가능
- 다중회귀에서 상관이 있는 상황일 때 다중공선성이 발생, 회귀계수 추정이 불안정해지는 문제 발생 - 차원의 저주
표본크기가 충분하지 않은 상황이라면, 회귀계수를 올바르게 추정할 수 없는 문제가 생긴다.
주성분분석
제1주성분 : 새로운 축은 데이터 퍼짐이 가장 커지는 방향으로 설정
제2주성분 : 제1주성분와 수직 방향이고 데이터 퍼짐이 가장 커지는 방향으로 설정

인자분석
데이터 내에서 잠재적인 요인을 추정하여, 여러변수들이 그 요인들에 의해 어떻게 설명될 수 있는지 알아보는 통계적 기법이다.
주로 차원 축소의 한 방법으로 사용되며, 변수 간의 관계를 통해 잠재적인 구조를 이해하는 데 도움을 준다.
목표 : 여러 변수들이 서로 연관되어이 있을 때, 이를 설명할 수 있는 공통된 잠재적 요인을 찾는 것
예 : 심리적 특정이 하나의 공통된 요인인 정신 건강으로 설명될 수 있다.
기계학습 입문
기계학습이란?
- 비지도 학습
- 지도 학습
- 강화학습
강화학습 예
통계학과 기계학습의 차이
통게학은 작은 표본크기를 가진 데이터를 대상으로 하며, 설명이나 해석을 중시하는 경향
기계학습은 대량의 데이터를 대상으로 하고, 예측을 중시하는 경향이 있습니다.
통계학의 선형회귀는 단순한 모형으로 쉽게 해석 가능
기계학습 모형은 복잡하기(비선형, 파라미터 많음)때문에 모형 해석이 어렵다.
일반적으로 예측 성능이 높다.
비지도학습
비지도학습이란?
정답 데이터가 없으며, 데이터의 배후에 있는 구조를 올바르게 추출하려는 목적으로 사용
1. 비슷한 데이터 집합을 발견하는 군집 분석
2. 고차원 데이터를 적은 수의 차원으로 줄이는 차원 축소
군집분석
각 데이터가 어떤 군집에 속하는지를 구하는 방법
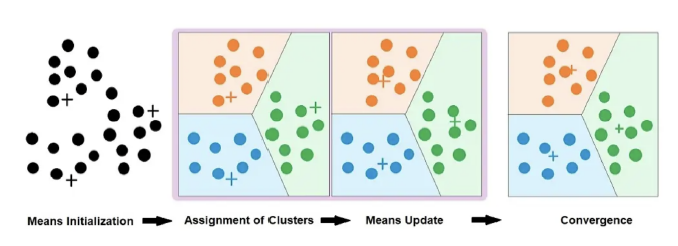
1. 군집 개수 k 구하기
2. 각 데이터에 무작위로 군집 할당
3. 각 군집의 중심 위치를 구하기
4. 데이터마다 가장 근접한 군집을 할다앟고 중심 위치를 다시 계산
계층적 군집화
모든 데이터가 다른 군집에 속하는 상태에서 시작하여, 가장 거리가 가까운 군집끼리 순서대로 합쳐 나가는 방식
덴드로그램으로 시각화가 가능하다.
군집 개수는 미리 정해지지 않으며, 어느 단계에서 바라보느냐에 따라 달라진다.
결과에는 분석자의 자의성이 개입된다는 것 또한 염두에 두어야 한다.
PCA 이외의 차원 축소 방법
주성분분석은 선형 상관관계에 기반을 두므로, 비선형관계에는 적용 할 수 없다는 문제가 있다.
이와 달리 t-SNE(t-distributed Stochastic Neihgbor Embedding)는 복잡한 비선형관계에도 적용할 수 있는 방법이다.
그밖에도 UMAP(Uniform Manifold Approximation and Projection)가 있다.


PCA(n=2)에는 잘 나눠지지 않은 반면 t-SNE, UMAP은 잘 구분이 된 것을 볼 수 있다.
지도학습
지도학습이란?
특정 x 값일 때, y가 어떤 값이 되는지에 관한 데이터를 바탕으로 그 관계를 학습해 나가는 방법입니다.
모형의 출력과 실제 y의 차이를 손실함수 정식화하고, 이를 최소화하는 파라미터를 구하는 것이 된다.
반응 변수가 y가 양적 변수일 때는 회귀
질적변수 일 때는 분류라 한다.
예측과 교차검증
동일 조건에서 얻을 수 있는 미지의 데이터(검증 데이터, 테스트 데이터)에 대해 설명변수 x로 반응변수 y를 예측하는 것
한쪽 데이터를 사용해 학습을 진행하고, 나머지 한쪽 데이터는 예측이 얼마나 좋은지 평가하는데 이용합니다.
이러한 방법을 교차검증이라 합니다.
대표적인것 K-분할 교차검증입니다.
K-분할 교차검증은, 데이터를 K개로 나눈 뒤 K-1개를 학습 데이터로, 남은 1개를 검증 데이터로 이용하여 예측 성능을 측정합니다. 이 과정을 K번 반복 시행해 예측 성능을 평균화하는 방법입니다.
또한, Leave-one-out 교차검증은 K-분할 교차검증에서 K=1인 경우에, 데이터 하나만을 골라 검증 데이터로, 나머지는 전부 학습 데이터로 삼는 방법으로, 이를 반복하여 모든 데이터가 한 번씩 검증 데이터가 되도록 하는 방법입니다.
학습 데이터에 대한 예측 성능은 높지만, 검증 데이터에 대한 예측 성능은 낮을 때, 과대적합이 일어났다고 표현합니다. 이는 학습 데이터의 무작위 데이터 퍼짐에도 모형이 적합해지고 말아, 검증 데이터를 제대로 예측하지 못한다는 것을 나타냅니다.
일반적으로 모형이 복잡할수록 과대적합이 일어나기 쉬우므로, 모형의 복잡도를 조정하는 요소를 손실함수에 도입할 때가 있는데, 이를 정칙화라 합니다
예측 성능 측정 1 : 이진 클래스 분류
반응변수가 2개의 클래스 A, B일 때를 이진 클래스 분류라 부릅니다.
- 위양성(False Positive : FP) : 실제는 음성이나 양성으로 판정
- 위음성(False Negative : FN) : 실제는 양성이나 음성으로 판정
- 진양성(True Positive : TP) : 양성을 양성으로 올바르게 판정
- 진음성(True Negative : TN) :음성을 음성으로 올바르게 판정
- 민감도(sensitivity or recall) : 양성을 양성이라 올바르게 판정할 비율
- 특이도(specificity) : 음성을 음성이라 올바르게 판정할 비율
- 양성 적중률(positive predictive value) : 양성이라 판정한 것이 실제로 양성일 비율
- 음성 적중률(negative predictive value) : 음성이라 판정한 것이 실제로 음성일 비율
- 정답률(accuracy) : 모든 판정 중 올바르게 예측한 것의 비율

일반적으로 민감도가 높을수록 특이도는 낮다는 상충 관계가 있습니다.
이에 민감도와 특이도 양쪽을 고려하여 예측 성능을 숫자로 나타내고자, 다음에 설명하는 ROC 곡선과 AUC를 사용하기도 합니다.
ROC 곡선과 AUC
분류의 예측 성능을 평가하는 RO(Receiver Operating Characteristic) 곡선
ROC 곡선은 이 역치가 작은 값에서 큰 값으로 점점 변할 때의 위양성률(=1-특이도)을 가로축으로, 민감도를 세로 축으로 하여 그려지는 곡선
ROC 곡선 결과를 하나의 숫자로서 나타낼 때는, ROC 곡선보다도 아랫부분의 넓이를 이용합니다.
이를 AUC(Area Under the Curve)라 부르며, 1에 가까울수록 예측 성능이 좋음을 뜻합니다.

예측 성능 측정 2 : 회귀
- 평균제곱오차(mean square error, MSE)
- 평균절대오차(mean absolute error, MAE)
- 결정계수 R
로지스틱회귀
로지스틱 회귀는 선형모형이므로, 단순한 분류만 가능한 선형분류기 입니다.
결정 트리와 랜덤 포레스트
결정 트리는 설명변수에 대해 x > 10이라면 가지 A, 그렇지 않다면 가지 B와 같은 조건 분기로 트리 구조를 만들어 데이터를 분류하는 방법입니다. 결정 트리의 예측 성능을 향상시키기 위해 여러 개의 결정 트리를 구성하고, 이를 다수결로 수행하는 랜덤 포레스트(random forest)라는 방법이 있다.
SVM
서포트 벡터 머신(Support Vector Machine, SVM)
각 데이터 점과의 거리가 최대가 디는 경계를 구하는 방법이며, 일반화 성능이 좋다고 알려졌습니다.
데이터를 커널 함수를 이용하여 변환함으로써, 비선형 분류도 가능한 방법입니다.
분리의 특징
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs, make_circles
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.neural_network import MLPClassifier
from mlxtend.plotting import plot_decision_regions
# 데이터 생성
def generate_data(linear=True):
if linear:
X, y = make_blobs(n_samples=300, centers=2, n_features=2, random_state=42)
else:
X, y = make_circles(n_samples=300, noise=0.1, factor=0.5, random_state=42)
return train_test_split(X, y, test_size=0.2, random_state=42)
# 모델 목록
models = {
"Logistic Regression": LogisticRegression(),
"Decision Tree": DecisionTreeClassifier(),
"SVM": SVC(kernel='rbf', probability=True),
"Neural Network": MLPClassifier(hidden_layer_sizes=(10, 10), max_iter=1000)
}
# 시각화 함수
def plot_models(models, X_train, X_test, y_train, y_test, title):
plt.figure(figsize=(12, 8))
for i, (name, model) in enumerate(models.items(), 1):
model.fit(X_train, y_train)
plt.subplot(2, 2, i)
plot_decision_regions(np.vstack((X_train, X_test)), np.hstack((y_train, y_test)), clf=model)
plt.title(name)
plt.suptitle(title)
plt.show()
# 선형 분리 가능한 데이터
X_train, X_test, y_train, y_test = generate_data(linear=True)
plot_models(models, X_train, X_test, y_train, y_test, "Linearly Separable Data")
# 선형 분리 불가능한 데이터
X_train, X_test, y_train, y_test = generate_data(linear=False)
plot_models(models, X_train, X_test, y_train, y_test, "Non-Linearly Separable Data")

문제의 종류에 따라 각 방법의 성능에 차이가 나므로 여러 방법을 시험해 보고 예측 성능을 비교하는 것이 좋습니다. 또한 결정 트리와 같이 분기 조건을 이용하여 쉽게 해석하는 방법도 있습니다. 따라서 적당한 수준에 예측 성능을 해석하고 싶을 때, 해석 없이 예측 성능 만을 향상시키고자 할 때 등, 분석 목적에 따라 방법을 선택하는 것이 바람직 합니다.
'Statistics' 카테고리의 다른 글
| [통계 101 x 데이터 분석] 모형 (0) | 2025.02.07 |
|---|---|
| [통계 101 x 데이터 분석] 베이즈 통계 (1) | 2025.02.06 |
| [통계 101 x 데이터 분석] 인과와 상관 (0) | 2025.02.06 |
| [통계 101 x 데이터 분석] 가설검정의 주의점 (0) | 2025.02.05 |
| [통계 101 x 데이터 분석] 통계 모형화 (3) | 2025.02.01 |