

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 파이썬 머신러닝 완벽가이드
- 티스토리챌린지
- 스파르타
- harkerrank
- 회귀분석
- 오블완
- 중회귀모형
- SQL
- 미세먼지
- wil
- 파이썬 철저입문
- 프로젝트
- 파이썬 철저 입문
- 실전 데이터 분석 프로젝트
- 내일배움캠프
- 스파르타 코딩
- 파이썬 머신러닝 완벽 가이드
- 프로그래머스
- MySQL
- Cluster
- 파이썬
- 웹 스크랩핑
- 텍스트 분석
- 파이썬 완벽 가이드
- hackerrank
- TiL
- 내일배움카드
- 내일배움
- 스파르타코딩
- R
- Today
- Total
OkBublewrap
[통계 101 x 데이터 분석] 인과와 상관 본문
인과관계 밝히기
우리가 사는 세상은 원인과 결과, 즉 인과관계로 넘쳐 나며, 복잡하게 얽힌 네트워크를 구성하고 있습니다.
인과관계를 밝히는 일이 그리 쉬운 일이 아닙니다.
인과관계와 상관관계
인과관계
원인과 결과의 관계 (원인 → 결과)
상관관계
데이터에서 보이는 관련성
어떤 특정한 조합이 일어나기 쉽다는 것이고,
수학적으로 말하면 확률변수 사이가 독립이 아니라는 것을 뜻한다.
중첩요인
두 변수에 관련된 외부 변수가 존재할 때, 이를 중첩이라 한다.
인과-상관-허위상관
상관관계란 2개 요소 X, Y가 있을 때 X가 커지면 Y도 커지고(또는 작아지고), X가 작아지면 Y도 작아지는(또는 커지는) 관계였습니다. 인과관계는 없지만 상관관계는 있을 때, 이를 허위상관이라 합니다.
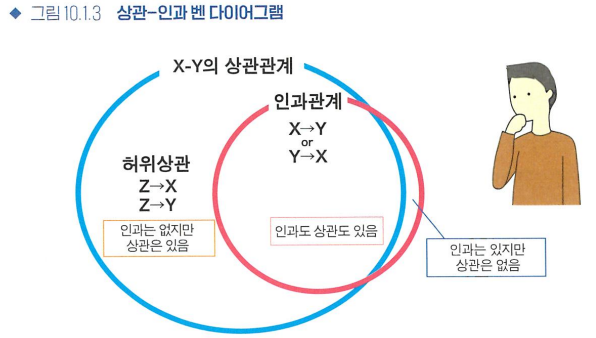
상관과 인과를 나타낸 벤 다이어그램, X-Y상관관계가 있지만 인과관계는 없을 때, 이를 허위상관이라 합니다. 인과관계는 있지만 경우도 있고, 인과관계가 없는 경우도 있습니다. 상관관계가 있다는 사실만으로는 이러한 가능성을 구별할 수 없습니다.
인과관계를 알면 할 수 있는 일
인과관계를 알면 상관관계를 알 때보다 더 많은 것을 이해할 수 있습니다.
인과관계를 밝히는 것이 왜 그렇게 중요한지는 아침밥을 먹임으로써 성적을 올리는 개입이 가능하다는 데 있습니다. 원인 변수를 변화시킴으로써, 결과 변수를 바꿀 수 있다는 말입니다.
상관관계를 알면 할 수 있는 일
상관관계가 반드시 인과관계를 의미하지는 않는다고 해도, 상관관계를 아는 것 역시 하나의 중요한 결과입니다.
상관관계를 아는 것 역시 하나의 중요한 결과입니다. 상관관계가 있다면 그 사이에 인과관계가 존재할 가능성이 있습니다.
인과관계를 명확히 하기 전 단계로서 상관관계를 이용하여 인과와 관련된 변수 후보를 압축해 갈 수도 있습니다.
상관관계는 2개 변수 X,Y 사이의 관련성이므로, 한쪽 변수 변수로부터 또 다른 변수를 예측할 수 있습니다.
인과관계와 상관관계의 다양한 사례
허위상관의 예
유명한 예로, 아이스크림 매출과 수영장 익사 사고에 양의 상관이 있다는 이야기가 있습니다.
아이스크림 매출이 오를수록 익사 사고 수도 많아지고, 아이스크림 매출이 줄어들수록 익사 사고수도 적어진다는 관련성입니다.
이 경우에는 중첩요인인 기온이 수영장의 익사 사고 수와 아이스크림 매출에 각각 영향을 줍니다.
기온이 높을수록 아이스크림이 더 많이 팔리고, 수영장에 가는 사람이 많아지므로 익사 사고가 늘어난다.
시간은 중첩요인이 되기 쉬움
중첩요인이 되기 쉬운 변수에는 시간 또는 나이가 있습니다.
시간과 함계 증가(감소)하는 X와 Y는 당연히 상관관계입니다.
초콜릿 소비량과 노벨상 수상자 수
국가별 초콜릿 소비량과 노벨상 수상자 간 양의 상관이 있다는 내용이 실렸습니다.
이 현상 배경에는 GDP가 중첩요인으로 작용한다고 생각할 수 있습니다.
우연히 생긴 상관
어떤 해의 니콜라스 케이지가 출연한 영화 편수와 그 해의 수영장 익사 사고 수 사이의 양의 상관입니다.
상관관계가 있다고 해도 이 둘에 공통으로 영향을 주는 제3의 변수가 존재하는 것이 아니라,
우연히 생긴 상관이라 생각할 수 있습니다
⚠️ 수많은 변수를 마구잡이로 해석하면 통계적으로 유의미한 결과를 얻을 수도 있다는 문제입니다.
무작위 통제 실험
인과관계를 밝히려면
인과관계 발견이 어려운 이유 중 하나는 중첩요인의 존재입니다.
어째서 중첩요인이 있으면 인과관계를 발견하기 어려워지는지를, 음주와 폐암의 예로 설명
관찰 데이터에서 음주 집단과 금주 집단사이 폐암 밟병률을 비교하면,
분명히 음주 집단에서 폐암 발병이 많다는 것을 알 수 있습니다.
그러나 음주 집단과 금주 집단의 흡연/비흡연 비율은 애당초 서로 다릅니다.
이렇게 해서는 흡연 효과가 포함되어 버리므로, 음주가 페암폐암 발병에 미치는 효과를 비교하려 해도, 그것이 음주 효과 때문인지, 흡연 효과 때문이지 구별할 수 없습니다. 따라서 음주가 폐암에 미치는 효과를 알고자 한다면, 음주 이외의 요인을 동일하게 하지 않으면 안 됩니다.
.
무작위 통제 실험
변수 X에서 변수 Y로서의 인과효과를 추정하는 가장 강력한 방법은 무작위 통제 실험입니다. 알고자 하는 요인인 변수 X에 표본을 무작위로 할당하고 개입 실험을 수행한 다음, 변수 Y와 비교하는 방법입니다.
중첩요인을 확인하지 않더라도,
그 효과를 무작위를 이용하여 무효화할 수 있으므로, 알고자 하는 변수의 효과만 추정 가능하기 때문입니다.
통계학에서의 인과관계
인과 추론의 근본 문제
X : 다이어트, Y = 다이어트를 한 몸무게 일 때 둘 다 관측할 수 없기 때문이다.
무작위 통제 실험의 이론적 배경
인과 추론의 근본 문제 때문에, 개인 수준에서는 인과를 알 수 없습니다. 이에 개인 수준이 아닌 집단 수준을 생각하여, 인과의 평균적인 효과를 고려하게 된다.
$$ \tau = E[Y^{(1)}-Y^{(0)}] = E[Y^{(1)}] - E[Y^{(0)}] $$
$ E[Y^{(1)}] $ 과 $ E[Y^{(0)}] $는 각각 다이어트를 했을 때의 기댓값과 하지 않았을 때의 기댓값을 나타냅니다.
그러나 이 경우에도 다이어트를 했을 때와 하지 않았을 때 모두를 관찰할 수는 없습니다.
실제로 관찰할 수 있는 것은 다이어트를 하는 집단에 할당된 사람의 몸무게와, 다이어트를 하지 않는 집단에 할당된 사람의 몸무게
간 기댓값 차이인 다음 값입니다.
$$ \tau' = E[Y^{(1)} | X = 1] = E[Y^{(0)}| X=0] $$
$ E[Y^{(1)} | X=1] $ 또는 $ E[Y^{(0)} | X=0] $ 은 조건부 기댓값으로, 다이어트를 하는 집단에 할당된 사람으로 한정한 몸무게의 기댓값입니다.
$$ \tau' = E[Y^{(1)} - Y^{(0)} | X = 1] + E[Y^{(0)} | X=1] - E[Y^{(0)} | X =0] $$
$ E[Y^{(1)} - Y^{(0)} | X = 1] $
- 다이어트를 한 사람들(X=1)이 다이어트를 했을 때와 안 했을 때의 몸무게 차이의 평균
- 즉, 다이어트의 실제 효과(개별 처치 효과의 평균)
$ E[Y^{(0)} | X=1] $
- 다이어트를 한 사람들이 만약 다이어트를 하지 않았다면 가질 몸무게의 기댓값
- 즉, 다이어트 그룹이 원래 가졌을 몸무게를 의미
$ E[Y^{(0)} | X =0] $
- 다이어트를 하지 않은 사람들이 실제로 가진 몸무게의 평균
$$ E[Y^{(1)}|X=1]-E[Y^{(0)}|X=0] =0 $$
- 다이어트를 한 사람들(X=1)의 평균 몸무게(다이어트 후)
- 다이어트를 하지 않은 사람들(X = 0)의 평균 몸무게(다이어트 없이 자연적으로 유지된 체중)
따라서, 위 식을 추정함으로써 인과효과를 추정할 수 있다.
구체적으로는 다이어트를 하는 집단과 하지 않는 집단으로 피험자를 무작위 할당하고, 반년 후 t 검정 등으로 2개 집단 간 몸무게를 비교하면 된다.
선택편향
관찰 데이터 등 무작위 할당이 아닌 경우에, 다이어트를 하는 사람과 하지 않는 사람에게서 잠재적인 몸무게 차이를 발견할 때가 있습니다.
예를 들어 다이어트에 의욕적인 사람은 애당초 몸무게가 많이 나가는 사람이라고 생각할 수 있다.
그렇다면 추정된 $ \tau' $는 원래 알고자 하는 효과 $ \tau $에 편향이 더해진 값이 된다.
지금까지 여러 번 등장한 중첩요인의 존재가 선택편향을 발생시켰기 때문에, 인과관계를 밝혀 내기가 어려웠던 것이다.
통계적 인과 추론
인과효과를 추정하는 또 다른 방법
개입 실험을 하기에는 윤리적인 문제가 있거나 개입 자체가 불가능할 때가 있기 때문에 통계적 인과적 추론이라는 방법을 쓴다.
다중회귀
중첩에 대처하는 수단으로, 다중회귀분석을 사용할 수 있다.
원인변수를 설명변수 x, 결과변수를 반응변수 y로 하고, 여기에 중첩요인 z를 설명변수로 추가하여 다음과 같이 다중회귀 모형을 만든다.
$$ y = a + b_{1}x + b_{2}z $$
편회귀수는 다른 설명변수와의 상관을 제거한 x의 영향이라고 해석할 수 있으므로, 인과효과를 나타내게 된다.
그러려면 생각할 수 있는 중첩요인을 측정해 모형에 도입하는 것이 중요합니다.
이렇게 중첩요인을 포함하는 것을 조정한다고 표현한다.
층별 해석
통계적 인과 추론 방법으로, 중첩요인을 기준으로 데이터를 몇 가지 그룹(층)으로 나누어, 각 층 안에서 중첩요인의 효과를 가능한 한 작게 하는 방법이 있다.
경향 점수 짝짓기
원인변수 = 0인 집단과 원인변수=1인 집단에서 비슷한 중첩요인을 가진 데이터를 골라 쌍으로 만드는, 짝짓기라는 방법이 있다.
실험 연구에서는 무작위 배정을 통해 처치 군과 대조군이 유사하게 구성되므로, 처치 효과를 쉽게 측정할 수 있다.
하지만, 관찰 데이터는 처치받은 사람과 받지 않은 사람이 본래부터 다를 가능성이 크다.
이러한 사전 차이를 줄이기 위해 경향 점수를 사용한다.
이중차분법
서로 다른 집단 A, B에 대해 A에는 처리르 가하고 B에는 가하지 않은 연구 설계에서는, 중첩요인에 따라 인과효과의 추정이 어려울 때가 있다. 이럴 때는 시간 축을 도입, 집단 간 차이에 대해 다시 한번 처리 전후의 차분을 취함으로써 인과효과를 추정할 수 있다.
단순 비교나 경향 점수 짝짓기와 같은 방법을 사용해도, 여전히 시간에 따른 외부 요인이 처치 효과 추정에 영향을 미칠 수 있다.
이중 차분법은 이러한 공통적인 시간 변화 요인을 제거하고, 처치가 실제로 미친 영향을 식별하는 데 도움을 준다.
'Statistics' 카테고리의 다른 글
| [통계 101 x 데이터 분석] 통계분석과 관련된 그 밖의 방법 (0) | 2025.02.06 |
|---|---|
| [통계 101 x 데이터 분석] 베이즈 통계 (1) | 2025.02.06 |
| [통계 101 x 데이터 분석] 가설검정의 주의점 (0) | 2025.02.05 |
| [통계 101 x 데이터 분석] 통계 모형화 (3) | 2025.02.01 |
| [통계 101 x 데이터 분석] 상관과 회귀 (0) | 2025.01.28 |