

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 파이썬 철저 입문
- 파이썬 머신러닝 완벽 가이드
- TiL
- 파이썬 철저입문
- 스파르타코딩
- 중회귀모형
- 파이썬 머신러닝 완벽가이드
- 스파르타 코딩
- 프로그래머스
- Cluster
- hackerrank
- wil
- 미세먼지
- 내일배움캠프
- 프로젝트
- SQL
- 내일배움카드
- 텍스트 분석
- harkerrank
- 파이썬
- 티스토리챌린지
- 회귀분석
- 오블완
- MySQL
- 스파르타
- 실전 데이터 분석 프로젝트
- 파이썬 완벽 가이드
- 웹 스크랩핑
- R
- 내일배움
- Today
- Total
OkBublewrap
실전 데이터 분석 프로젝트(5) 본문
전에 이어서 분석을 하고 싶은 상수도에서만 대해 분석을 진행
df_seoul_water = df_seoul[df_seoul['부서레벨2'] == '상수도사업본부']
df_seoul_water.head(5)
부서명을 조회를 해봤다. 부서명에는 엄청 많은 부서명이 존재를 했다. 일단 필요없는 부서레벨1, 부서레벨2는 삭제하고 부서명을 표시해봤다.
# 부서레벨1, 부서레벨2 열 삭제
df_seoul_water_x = df_seoul_water.drop(['부서레벨1', '부서레벨2'], axis = 1)
# 부서명 고유값
df_seoul_water_x['부서명'].unique()array(['급수부', '구의아리수정수센터 정수과', '강북정수센터 정수시설과', '상수도사업본부 영등포아리수정수센터 정수과',
'구의아리수 정수센터 정수시설과', '총무과', '강남수도사업소현장민원과', '정수과', '원수관리과',
'뚝도아리수 정수센터', '수도자재 (기관)', '수도자재 (시책)', '수도자재 (부서)',
'서부수도사업소 시설관리과', '강동수소사업소시설관리과', '강동수도사업소 급수운영과', '강동수도사업소 요금과',
'강동수도사업소 행정지원과', '강동수도사업소 ', '광암아리수정수센터 정수시설과',
'영등포아리수정수센터 행정관리과', '상수도사업본부 시설안전부', '요금관리부 요금제도과', '요금관리부 재무회계과',
'요금관리부 계측관리과', '광암아리수정수센터 정수운영과', '광암아리수정수센터 정수시설과',
'북부수도사업소 현장민원과', '요금과', '북부수도사업소 요금과', '서부수도사업소 현장민원과',
'강남수도사업소 행정지원과', '남부수도사업소 행정지원과', '강남수도사업소 행정지원과',
'영등포아리수정수센터 정수시설과', '생산부', '수질분석부', '수질분석부 신물질분석과', '수질분석부 먹는물분석과',
'수질분석부 미생물검사과 ', '상수도사업본부 경영관리부', '연구기획과', '전략연구과',
'암사아리수 정수센터 정수시설과', '암사아리수 정수센터 정수과', '암사아리수 정수센터 행정관리과', '현장민원과',
'급수운영과', '남부수도사업시설관리과', '북부수도사업소 행정지원과', '남부수도사업소 요금과',
'강서수도사업소 현장민원과', '강남수도사업소 요금과', '남부수도사업소 급수운영과',
'서울물연구원 수도연구부 물순환연구과', '서울물연구원 수도연구부 재료연구과', '서울물연구원 수도연구부 수처리연구과',
'서울물연구원 수도연구부', '서울물연구원 수도연구부 배급수연구과', '상수도사업본부 강서수도사업소', '시설관리과',
'행정지원과', '중부수도사업소', '구의아리수 정수센터 행정관리과', '동부수도사업소 시설관리과',
'동부수도사업소 현장민원과 ', '동부수도사업소요금과', '동부수도사업소', '동부수도사업소 행정지원과',
'상수도사업본부 강서수도사업소 행정지원과', '서부수도사업소 행정지원과', '강북아리수정수센터 행정관리과',
'상수도사업본부 생산부', '강남수도사업소시설관리과', '수도자재 (정원)', '강동수도사업소',
'강동수도사업소 현장민원과', '요금관리부 전산정보과', '상수도본부경영관리부', '북부수도사업소시설관리과',
'상수도사업본부 강서수도사업소 시설관리과', '동부수도사업소 급수운영과', '미래전략연구센터',
'수질분석부 미생물검사과', '수질분석부 수질연구과', '수질분석부 먹는물분석과 ', '수질분석부 수질연구과 ',
'상수도사업본부생산부', '수질분석부 신물질분석과 ', '강동수도사업소행정지원과', '서부수도사업소급수운영과',
'강남수도사업소 급수운영과', '수질분석부 미생물검사과', '강북아리수정수센터 정수과', '수도연구부 물순환연구과',
'수도연구부 재료연구과', '서울물연구원 수도연구부 ', '강동수도사업소 ', '수질분석부 수질연구과',
'상수도사업본부 경영관리뷰', '강동수소사업소 시설관리과', '남부수도 사업소 급수운영과', '강남수도사업소행정지원과',
'동부수도사업소 현장민원과', '강남수도사업소급수운영과', '북부수도사업소 시설관리과',
'서부수도사업소현장민원과', '수도연구부', '수도연구부 수처리연구과', '수도연구부 배급수연구과',
'광암아리수정수센터 행정관리팀', '서부수도 사업소', '강동수도사업소시설관리과', '물순환연구과', '재료연구과',
'배급수연구과', '수처리연구과', '행정관리팀', '북부수도사업소행정지원과', '수질분석부 수질연구과 외 3과',
'강동수도사업소 시설관리과', '구의아리수 정수센터 정수시설과', '영등포아리수정수센터 정수과',
'강서수도사업요금과', '서부수도사업소행정정원과', '서울물연구원수도연구부', '상수도사업본부강서수도사업소 시설관리과',
'요금관리부 게측관리과', '요금관리부 요금제도과', '강서수도사업소', '서부수도사업소행정지원과',
'강서수도사업소요금과', '상수도사업본부 강서수도사업소', '강서수도사업소 요금과',
'상수도사업본부 강서수도사업소 행정지원과', '서울물연구원수도연구부 (수처리연구과)',
'서울물연구원수도연구부 (재료연구과)', '서울물연구원수도연구부 (물순환연구과)',
'서울물연구원수도연구부 (수처리연구과)', '서울물연구원수도연구부 (재료연구과)', '요금관리 요금제도과',
'서울물연구원수도연구부(물순환연구과)', '서울물연구원수도연구부(재료연구과)',
'서울물연구원수도연구부 (배급수연구과)', '서울물연구원수도연구부 (배급수연구과)',
'서울물구원수도연구부 (물순환연구과)', '서수도사업소 행정지원과', '강서수도사업소 행정지원과',
'서울물연구원수도연구부 (물순환연구과)', '서울물연구원수도연구부 (수도연구부장)', '강북아리수정수센터원수관리과',
'서부수도 행정지원과', '강북아리수 정수센터 원수관리과',
'강북아리수 정수센터 원수관리과', '서울물연구원수도연구부장실', '수질연구과 미생물검사과',
'정수시설과', '서울물연구원 (수도연구부장)'], dtype=object)엄청 많은 부서명이 존재, 총 158개의 부서가 존재했다. 행정을 좀 묶을 필요가 보인다.
https://arisu.seoul.go.kr/c5/sub4_3.jsp
상수도사업본부 > 사업본부 > 기구 및 부서 > 직원소개
<!-- > 사업본부 > 기구 및 부서 > 직원소개 --> <!-- --> 직원소개 수도관련민원은 (02) 120번 ※ 업무 문의 전화 시 반드시 국번(02) 입력
arisu.seoul.go.kr

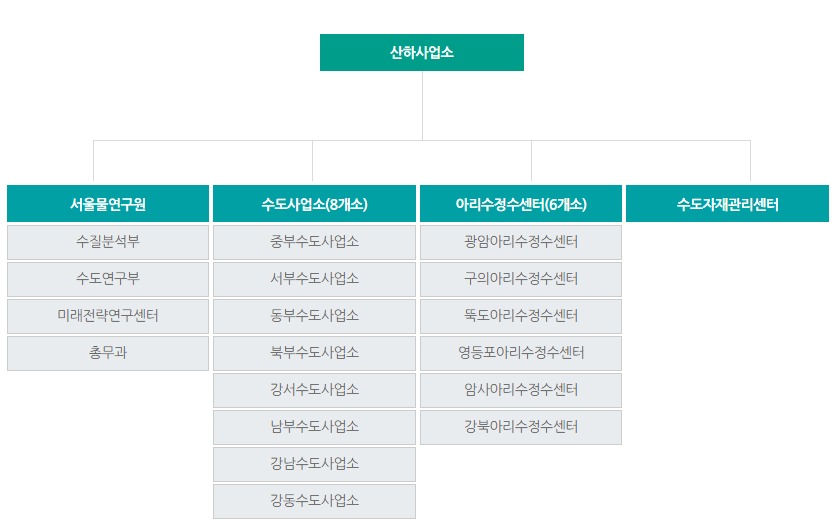
행정 분류는 이렇게 나누어진다. 다른 부분을 보고 합칠지 봐야 겠다.
# 가장 많이 쓴 집행 금액
df_seoul_water_x['집행금액'].sort_values(ascending = False).head(5)76865 6690000.0
36662 4290000.0
87951 3150000.0
13004 3132250.0
127954 3129300.0
Name: 집행금액, dtype: float64# 집행금액이 가장 높은 상위 5개의 인덱스로 데이터 추출
df_seoul_water_x.loc[df_seoul_water_x['집행금액'].sort_values(ascending = False).head(5).index.tolist()]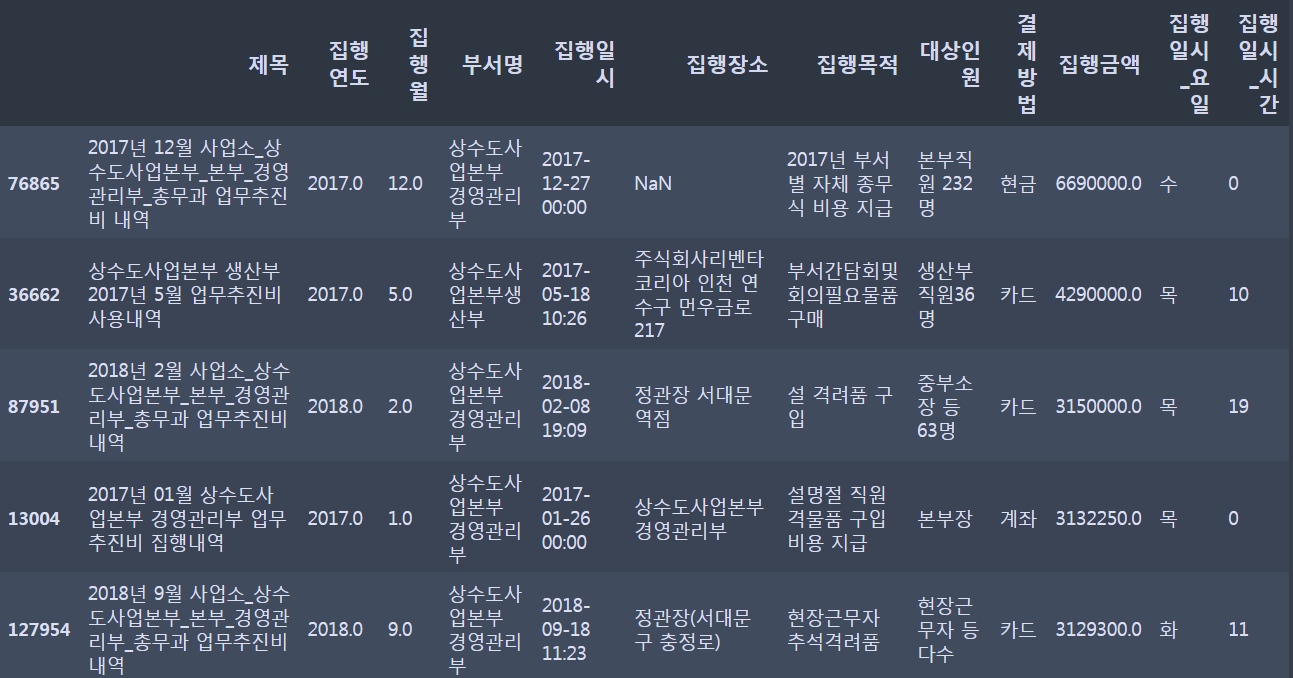
3,4,5는 명절 격려품 회의에 필요한 물품, 총무식 비용이 상위 5개로 나타났다. 집행목적에 대해서 좀 알 필요가 있어 보인다.
# 하나씩 보기 위해서 for구문 이용
for i in range(1, len(df_seoul_water_x['집행목적'].unique())):
print(df_seoul_water_x['집행목적'].unique()[i])7074개의 집행 목적이 적혀 있다. 간담회, 경조사비 등등 비슷한 내역이 존재하는 것 같다.
Group by 부서명
df_seoul_water_x[['부서명','집행금액']].groupby('부서명').sum().sort_values('집행금액', ascending = False)
경영관리부에서 집행금액의 합이 제일 큰 것을 볼 수가 있다. 위에 나온 행정부서로 그룹화를 해서 진행을 할려고 생각을 했으나 텍스트가 너무 복잡해서 진행을 하지 못했다. 그래서 마지막으로 상수도사업본부 경영관리부에만 분석을 하고 끝낼 생각이다. 생각보다 시간이 오래 걸릴 작업이 될 것 같다.
# 상수도사업본부 경영관리부
df_seoul_water_mng = df_seoul_water_x[df_seoul_water_x['부서명'] == '상수도사업본부 경영관리부']# 요일별 집행금액 시각화
expense_weekday = df_seoul_water_mng['집행일시_요일'].value_counts()
expense_weekday = expense_weekday.reindex(index = week_day_name)
expense_weekday.plot.bar(rot=0)
plt.title("요일별 업무추진비 집행 횟수")
plt.xlabel("요일")
plt.ylabel("집행 횟수")
plt.show()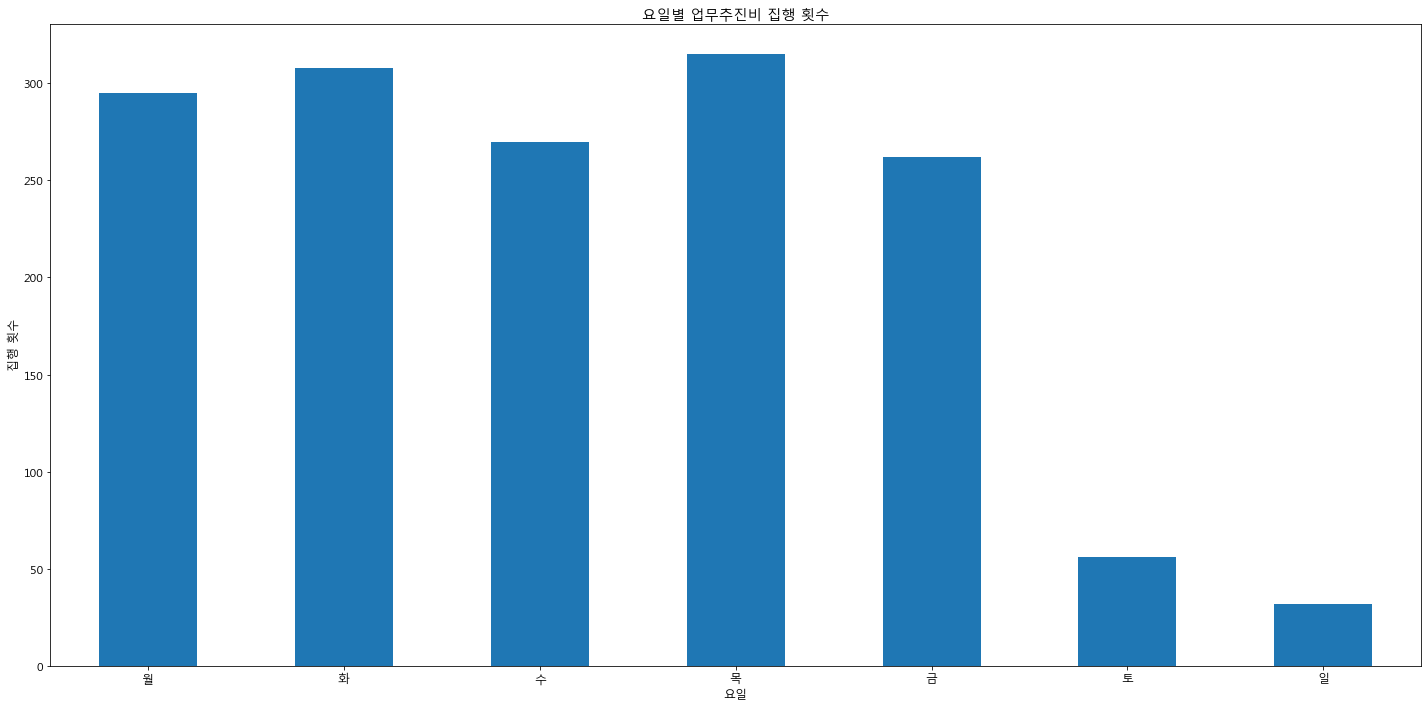
# 연도, 월별 집행금액 시각화
month_total = pd.pivot_table(df_seoul_water_mng, index = ['집행월'], values=['집행금액'],
aggfunc = sum)
year_month_total = pd.pivot_table(df_seoul_water_mng, index = ['집행월'], columns=['집행연도'],
values=['집행금액'], aggfunc = sum)
year_month_total.plot.bar(rot=0)
plt.ylabel('집행금액(억원)')
plt.title("업무추진비의 월별 집행금액")
plt.legend(['2017년', '2018년'])
plt.show()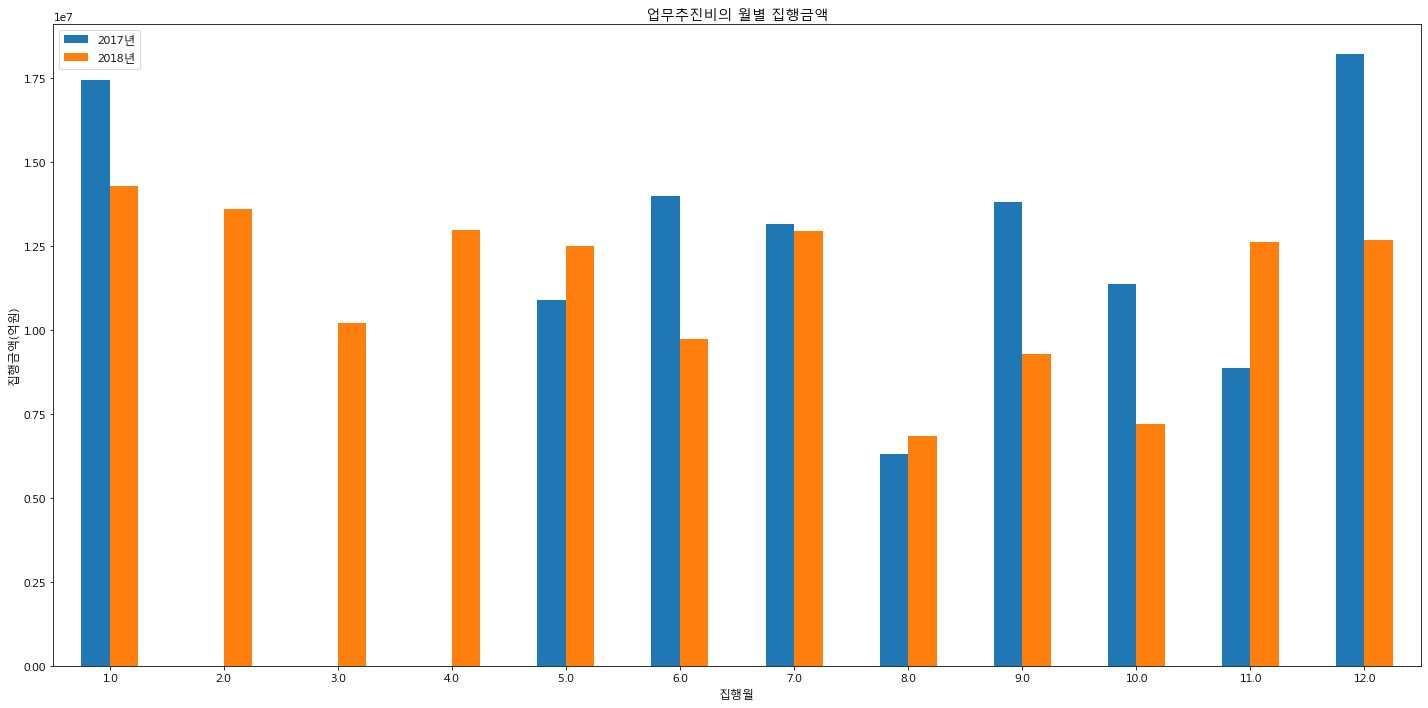
2월에서 4월까지 집행금액이 없는것을 볼 수가 있다. 이부분는 누락된 것 같다.
상수도사업본부 경영관리부 워드클라우드
우선 진행하고 싶은 것은 집행목적에 대해서 단어토큰화후 워드클라우드를 진행하는 것이였다.
java에 관해 오류가 떳으나 설치하고 진행을 하면서 해결이 되었다.
from konlpy.tag import Okt
okt = Okt()
# 원본 집행목적 문장
df_seoul_water_mng['집행목적'].iloc[0]
# '부속실 운영물품 구입(귤 등 5종)'
# 명사 단위로 자르기
okt.nouns(df_seoul_water_mng['집행목적'].iloc[0])
# ['부속', '실', '운영', '물품', '구입', '귤', '등', '종']
# 형태소 단위로 자르기
okt.phrases(df_seoul_water_mng['집행목적'].iloc[0])
# ['부속', '실', '운영', '물품', '구입', '(', '귤', '등', '5', '종', ')']
# 어절 단위로 자르기
okt.phrases(df_seoul_water_mng['집행목적'].iloc[0])
# ['부속실', '부속실 운영물품', '부속실 운영물품 구입', '귤 등 5종', '부속', '운영', '물품', '구입']명사만 추출을 했을때 '부속'하고 '실'이 떨어지긴 했지만 그리 중요한 문제는 아닌 것 같다. 목적은 단어 빈도수이므로
부속실을 포함하고 싶으면 어절 단위로 자르는 것이 제일 나아보인다. 그래서 어절 단위로 잘라서 분석을 진행하기로 했다.
phrases_list = []
for i in range(1538):
phrases_list.append(okt.phrases(df_seoul_water_mng['집행목적'].iloc[i]))
phrases_list[:3][['부속실', '부속실 운영물품', '부속실 운영물품 구입', '귤 등 5종', '부속', '운영', '물품', '구입'],
['2017',
'2017 옥내',
'2017 옥내 노후',
'2017 옥내 노후 급수관',
'2017 옥내 노후 급수관 교체사업',
'2017 옥내 노후 급수관 교체사업 추진',
'2017 옥내 노후 급수관 교체사업 추진 관련',
'2017 옥내 노후 급수관 교체사업 추진 관련 간담회',
'옥내',
'노후',
'급수',
'교체',
'사업',
'추진',
'관련',
'간담'],
['설명절',
'설명절 직원',
'설명절 직원 격물품',
'설명절 직원 격물품 구입비용',
'설명절 직원 격물품 구입비용 지급',
'설명',
'직원',
'격물',
'구입',
'비용',
'지급']]연도가 거슬리긴 하는데 워드클라우드를 그려보고 불용어 처리를 진행
# 단어 빈도수
from collections import Counter
noun = okt.nouns(str(phrases_list))
count = Counter(noun)
count
우려 했던 대로 부속실이 따로 나온 것을 볼 수 있다. 한 단어로 이루어진 단어는 제거
# 한 글자 키워드를 제거
remove_one_word = Counter({x : count[x] for x in count if len(x) > 1})
remove_one_word
단어 한개인 것은 제거가 된 것을 볼 수가 있다.
# 명사 빈도 상위 100개만 추출
noun_list = remove_one_word.most_common(100)
# Txt파일로 저장
with open("noun_list.txt",'w',encoding='utf-8') as f:
for v in noun_list:
f.write(" ".join(map(str,v))) #튜플 int값을 str 타입으로 전환 후 조인
f.write("\n")
# Txt파일 불러오고 워드클라우드 저장
filename = "noun_list.txt"
f = open(filename,'r',encoding='utf-8')
words = f.read()
wc = WordCloud(font_path='C:\Windows\Fonts\맑은 고딕\malgun.ttf', \
background_color="white", \
width=500, \
height=500, \
max_words=200, \
max_font_size=150, \
)
wordcloud_words = wc.generate(words)
wc.to_file('wordcloud.png')
# 워드클라우드 시각화
from IPython.display import Image
Image('wordcloud.png')
전에 말했던대로 간담회, 업무 추진비 이렇게 같이 붙여진 단어인데 따로 나온것을 볼 수 가있다. 현안은 뭘 뜻하는지 모르겠다. 집행 목적을 워드 클라우드로 분석을 했을 때 그리 크게 의미가 있었던 분석이 아니였던 것 같다.
'Python > 프로젝트' 카테고리의 다른 글
| @코스메 한국 브랜드 화장품 데이터베이스 구축(1) (3) | 2025.02.23 |
|---|---|
| Discord 미세먼지 Msg (0) | 2023.04.21 |
| 실전 데이터 분석 프로젝트(4) (1) | 2023.03.24 |
| 실전 데이터 분석 프로젝트(3) (0) | 2023.03.24 |
| 실전 데이터 분석 프로젝트(2) (0) | 2023.03.22 |



