

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 내일배움
- 중회귀모형
- 내일배움카드
- 파이썬 철저 입문
- 오블완
- 티스토리챌린지
- 스파르타 코딩
- 회귀분석
- 파이썬 완벽 가이드
- 실전 데이터 분석 프로젝트
- 텍스트 분석
- 프로젝트
- 파이썬
- 파이썬 머신러닝 완벽 가이드
- R
- 파이썬 머신러닝 완벽가이드
- 파이썬 철저입문
- 프로그래머스
- 미세먼지
- hackerrank
- 스파르타코딩
- SQL
- MySQL
- 내일배움캠프
- harkerrank
- TiL
- 스파르타
- wil
- Cluster
- 웹 스크랩핑
- Today
- Total
OkBublewrap
실전 데이터 분석 프로젝트(3) 본문
실제 데이터로 분석을 진행을 한다. 분석할 데이터는 서울시 업무 추진비 이다.
분석전 데이터를 불러와서 결합하고 처리하는 코드는 생략한다.
import pandas as pd
data_folder = 'C:/myPyCode/data/seoul_expense/'
years = [2016, 2017, 2018]
df_expense_all = pd.DataFrame()
for year in years:
expense_list_year_dir = data_folder + str(year) + '/'
expense_list_tidy_file = "{}_expense_list_tidy.csv".format(year)
path_file_name = expense_list_year_dir + expense_list_tidy_file
df_expense = pd.read_csv(path_file_name)
df_expense_all = df_expense_all.append(df_expense, ignore_index = True)df_expense_all.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 153402 entries, 0 to 153401
# Data columns (total 12 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 제목 143418 non-null object
# 1 부서레벨1 142698 non-null object
# 2 부서레벨2 142192 non-null object
# 3 집행연도 142350 non-null float64
# 4 집행월 142350 non-null float64
# 5 부서명 142271 non-null object
# 6 집행일시 142350 non-null object
# 7 집행장소 140883 non-null object
# 8 집행목적 142328 non-null object
# 9 대상인원 141594 non-null object
# 10 결제방법 142147 non-null object
# 11 집행금액 142350 non-null float64
# dtypes: float64(3), object(9)
# memory usage: 14.0+ MB데이터를 합치고 나온 결과물의 컬럼명들이다. 12개 컬럼으로 구성이 되어있다. 우선 업무 추진비에 대해서 알아야 하는데 투명한 재정을 위해서 돈이 어디서 쓰여는지 알수 있게 하는 것이다.
df_expense_all.head(5)
df_expense_all.tail(5)데이터프레임의 앞뒤로 보면

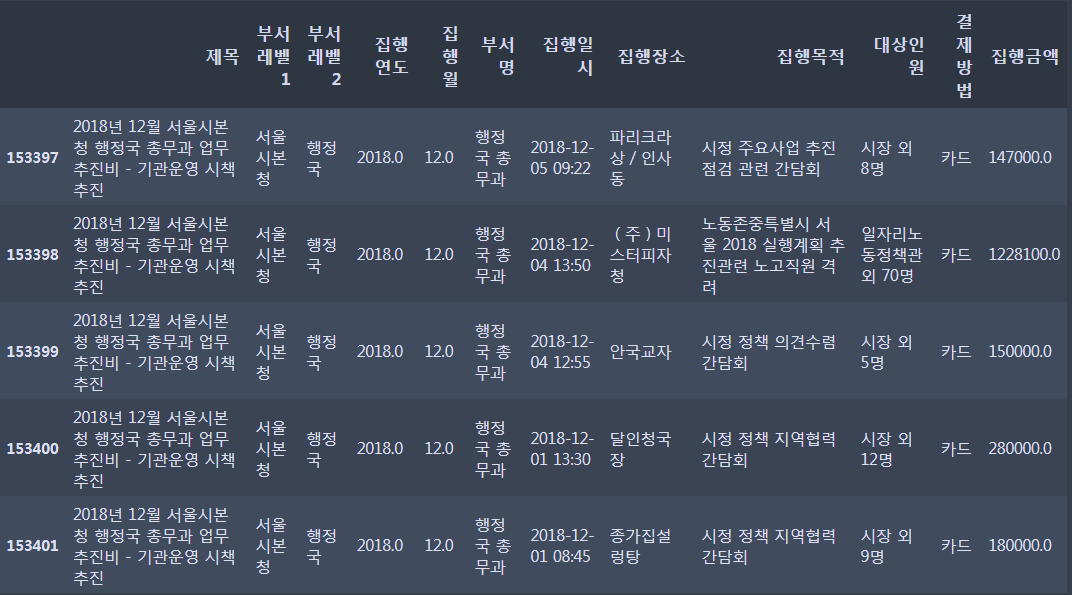
앞부분에는 Nan값이 뒷부분에는 데이터가 존재를 한다. 우선 결측값 처리를 하고 제목과, 집행일시에 데이터 변환을 해야겠다.
df_expense_all.isnull().sum()
# 제목 9984
# 부서레벨1 10704
# 부서레벨2 11210
# 집행연도 11052
# 집행월 11052
# 부서명 11131
# 집행일시 11052
# 집행장소 12519
# 집행목적 11074
# 대상인원 11808
# 결제방법 11255
# 집행금액 11052
# dtype: int64총 데이터 수는 십삼만개 정도 있고 결측값들은 만건정도가 존재 한다. 여기서 집행 금액이 중요하므로 집행금액이 없는 것은 삭제를 한다.
df_seoul = df_expense_all.dropna(subset=['집행금액'], how='any', axis=0)
df_seoul.isnull().sum()
# 제목 0
# 부서레벨1 0
# 부서레벨2 194
# 집행연도 0
# 집행월 0
# 부서명 79
# 집행일시 0
# 집행장소 1467
# 집행목적 22
# 대상인원 756
# 결제방법 203
# 집행금액 0
# dtype: int64집행금액이 nan인 행을 지웠는데 집행장소랑 대상인원은 많이 빈 값으로 나오는 것 같다.
제목
# 제목 뜯어보기
print("고유한 제목 개수 : ",len(df_seoul['제목'].unique()))
print(df_seoul['제목'].value_counts().head(10))
제목을 봤을 때 비슷한 제목의 내용이 있는 것 같다 서울시본청_행정국_총무과 업무추진비 내역에 앞부분만 다른 것을 확인을 할수 있다. 이부분은 다른 컬럼에 연도와 월을 표시해주는 것이 있기 때문에 없애고 진행을 해봐도 될 것 같다.
'201?년도 ?월 ' , '201?월 ??월 ' 이런 식으로 되어 있다. 이 부분은 문장에서 월을 찾아서 그 한칸뒤까지 삭제를 진행을 하면 될 것 같다. 전부다 월이 들어갔는지 확인을 하기 위해서 코드를 작성
df_seoul.shape
# (142350, 12)
# 제목 안에 월이 들어갔는지 확인
df_seoul[df_seoul['제목'].str.contains('월')].shape
# (141614, 12)736개의 컬럼이 '열'이 안들어간 것을 확인을 할 수 있다. 그 부분을 확인을 하기 위해서 제목인 열만 set으로 변경을 한 뒤 차집합으로 진행
set.difference(set(df_seoul['제목']),set(df_seoul[df_seoul['제목'].str.contains('월')]['제목'])){' 물재생시설과 업무추진비 집행 현황 ',
'2017.1. 어린이병원 약제과 부서운영업무추진비 집행내역',
'2017.2. 업무추진비 집행내역(자원순환과)',
'2017년 시민건강국 생활보건과 업무추진비집행 내역',
'2017년 업무추진비 등록',
'2017년 일자리노동정책관 일자리정책담당관 업무추진비 사용내역',
'2017년 조경과 업무추진비 내역',
'2017년 지역발전본부 동북권사업단 업무추진비 집행내역',
'교통방송 미디어정책실 업무추진비 사용내역(2017.04.)',
'교통방송 미디어정책실 업무추진비(2017.05) 사용내역',
'기후환경본부 대기관리과 업무추진비 집행 내역',
'도시계획과 업무추진비 사용내역(2017.5)',
'도시재생본부 도시활성화과 업무추진비 내역 ',
'도시재생본부 도시활성화과 업무추진비 등록 ',
'물순환정책과 업무추진비 집행내역(2017.02)',
'물순환정책과 업무추진비 집행내역(2017.03)',
'물순환정책과 업무추진비 집행내역(2017.04)',
'물순환정책과 업무추진비 집행내역(2017.05)',
'물재생시설과 업무추진비 집행 현황',
'물재생시설과 업무추진비 집행현황',
'미디어정책실 업무추진비(2017.01.) 집행내역',
'미디어정책실 업무추진비(2017.02.) 집행내역',
'미디어정책실 업무추진비(2017.03.) 집행내역',
'보존과학과 업무추진비 집행현황',
'복지정책과 업무추진비 공개',
'부서 업무추진비(시설과)',
'부서운영 업무추진비',
'서부공원녹지사업소 여의도공원 업무추진비 등록',
'서부공원녹지사업소 여의도공원관리사무소 업무추진비 내역서 공개',
'서울소방학교(구조구급교육센터) 업무추진비 집행내역',
'서울숲공원지원과 업무추진비',
'서울역사박물관 유물관리과 업무추진비 내역(18.2)',
'서울역사박물관 총무과 업무추진비 사용내역 공개(2017.5)',
'소방재난본부 현장대응단 2017년 5월 업무추진비 집행내역',
'시민봉사담당관 업무추진비 집행현황',
'어린이병원 약제과 2017.2. 부서운영업무추진비 집행내역 ',
'업무추진비 공개내역등록',
'업무추진비 공개내역등록(광암아리수정수센터 정수시설과)',
'영등포아리수정수센터 정수시설과 부서운영업무추진비 사용내역 공개',
'영등포아리수정수센터 정수시설과 부서운영업무추진비 집행내역',
'자연생태과 업무추진비 집행내역(2017.03)',
'행정2부시장실 업무추진비 집행내역',
'행정관리과 업무추진비 집행현황',
'행정지원과 업무추진비 집행현황',
'현장대응단 2017년 1월 업무추진비 집행내역',
'현장대응단 2017년 2월 업무추진비 집행내역',
'현장대응단 2017년 3월 업무추진비 집행내역',
'현장대응단 2017년 4월 업무추진비 집행내역'}생각보다 제목 상태가 규칙성이 복잡했다. 마지막 부분에 현장대응단 제목에는 월이 들어갔는데 왜 나온것인지는 잘 모르겠다. 일단 다른 열들을 뜯어보면서 제목을 어떻게 진행을 할 것인지 생각을 해봐야겠다.
df_seoul['부서레벨1'].value_counts()
# 서울시본청 85431
# 사업소 34412
# 소방재난본부(소방서) 15237
# 의회사무처 7270
# Name: 부서레벨1, dtype: int64부서레벨은 총 네개의 사용처가 있었다. 서울시본청, 사업소, 소방서, 의회사무처로 구성이 되어있다. 부서레벨2에는 더욱 세분화 되어있다. 부서레벨2에는 133개의 부서가 있다. 다음은 어디서 부서에 속해져 있는지 궁금해봐서 피벗테이블을 실행을 했다.
# 모든 열 보여주기
pd.set_option('display.max_rows', None)
# 부서별 총집행 수
df_seoul[['부서레벨1', '부서레벨2', '집행금액']].groupby(['부서레벨1','부서레벨2']).count()
# 부서별 총 집행금액 합
df_seoul[['부서레벨1', '부서레벨2', '집행금액']].groupby(['부서레벨1','부서레벨2']).sum()
# 그룹 시각화
df_seoul[['부서레벨1', '부서레벨2', '집행금액']].groupby(['부서레벨1','부서레벨2'], as_index = True)['집행금액'].count()
group_count.plot(kind = 'bar')

개수가 133개라서 뭐가 쓰인지도 잘 안보여서 부서레벨1 별로 시각화를 진행
'Python > 프로젝트' 카테고리의 다른 글
| 실전 데이터 분석 프로젝트(5) (0) | 2023.03.24 |
|---|---|
| 실전 데이터 분석 프로젝트(4) (1) | 2023.03.24 |
| 실전 데이터 분석 프로젝트(2) (0) | 2023.03.22 |
| 실전 데이터 분석 프로젝트(1) (0) | 2023.03.21 |
| wine_modeling(1) (0) | 2023.03.05 |



