

Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 웹 스크랩핑
- 파이썬 머신러닝 완벽 가이드
- 파이썬 철저입문
- 내일배움
- SQL
- MySQL
- 내일배움캠프
- 프로젝트
- hackerrank
- 스파르타
- TiL
- 내일배움카드
- 파이썬
- 파이썬 철저 입문
- 오블완
- 파이썬 완벽 가이드
- R
- harkerrank
- 파이썬 머신러닝 완벽가이드
- 스파르타코딩
- 실전 데이터 분석 프로젝트
- 중회귀모형
- 텍스트 분석
- 회귀분석
- 프로그래머스
- Cluster
- 미세먼지
- 스파르타 코딩
- wil
- 티스토리챌린지
Archives
- Today
- Total
OkBublewrap
실전 데이터 분석 프로젝트(4) 본문
부서레벨1 집행 비중
from matplotlib import pyplot as plt
pd.set_option('display.max_rows', None)
%matplotlib inline
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.rcParams["figure.figsize"] = (20, 10)
plt.rcParams["font.size"] = 12
plt.rcParams["figure.autolayout"] = Truedf_seoul_1 = df_seoul[df_seoul['부서레벨1'] == '서울시본청']
group_count_1 = df_seoul_1[['부서레벨1', '부서레벨2', '집행금액']].groupby(['부서레벨1','부서레벨2'], as_index = True)['집행금액'].count()
group_count_1.plot(kind = 'bar')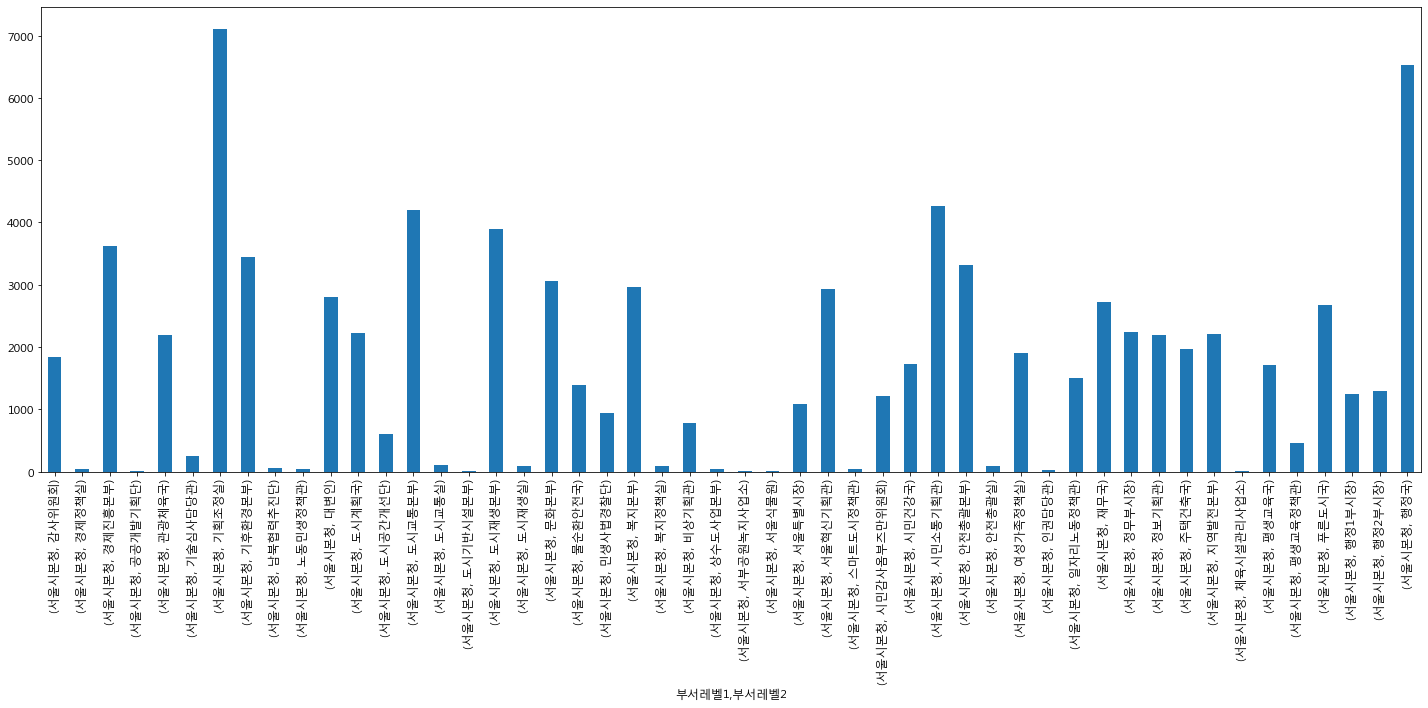
서울시본청에서는 기획조정실, 행정국에서 많은 건수가 나타난 것을 알 수 있다.
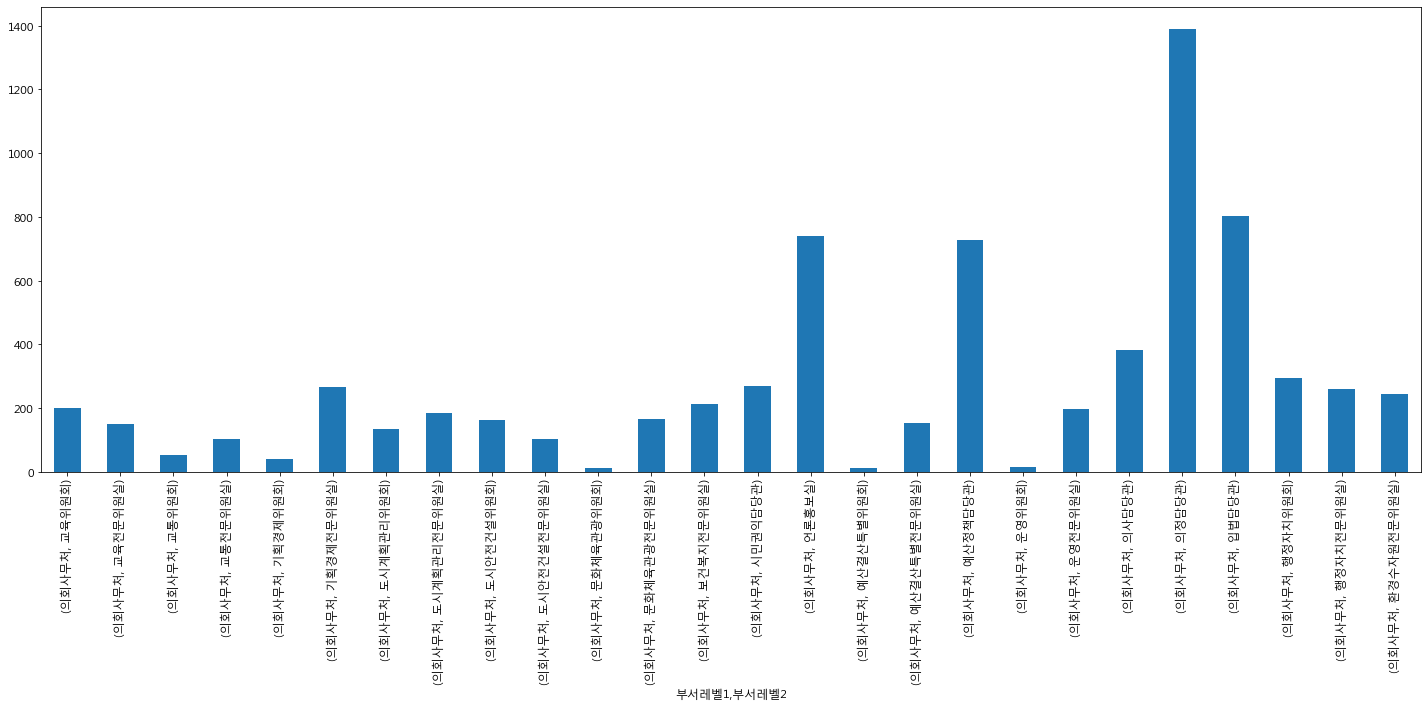
의회사무처에서는 의정담당관, 입법담당관에 많은 건수가 발생했다.
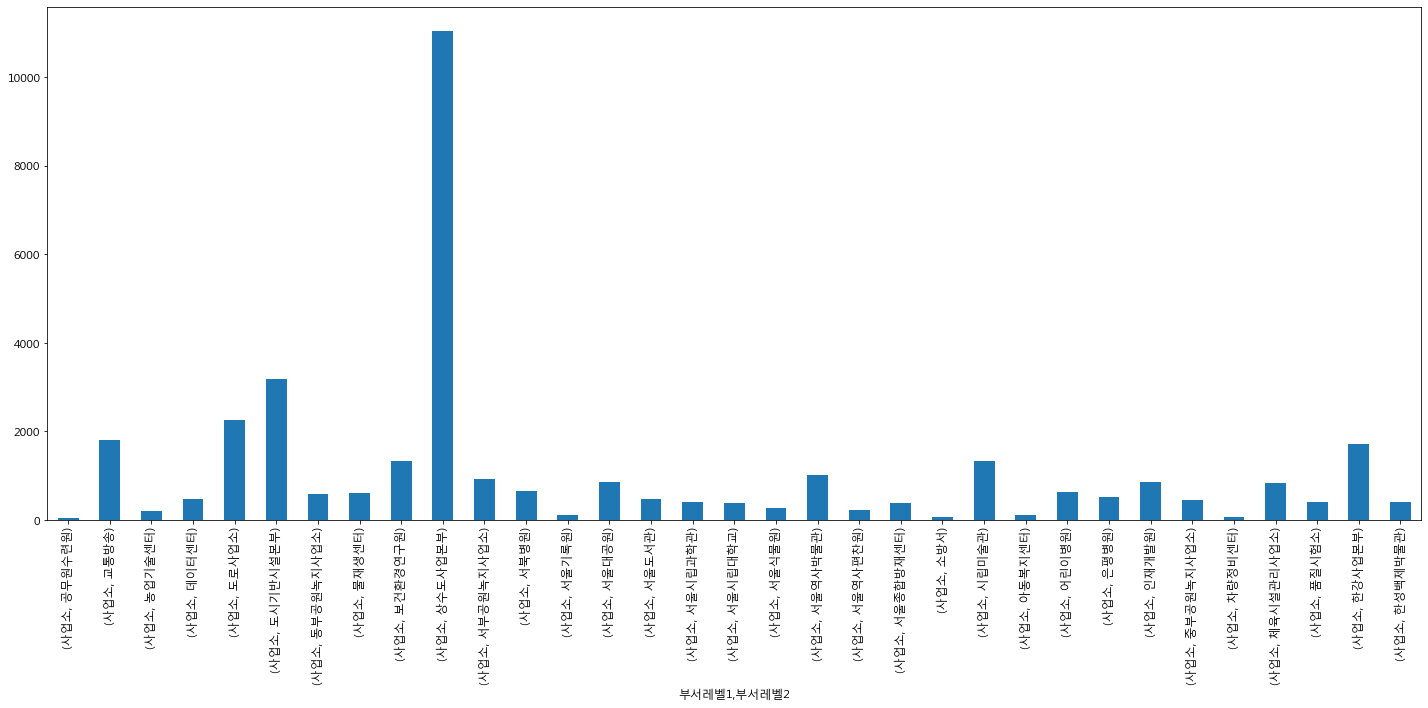
사업소에서는 상수도 사업본부에서 유독히 많은 건수가 발생을 했다.
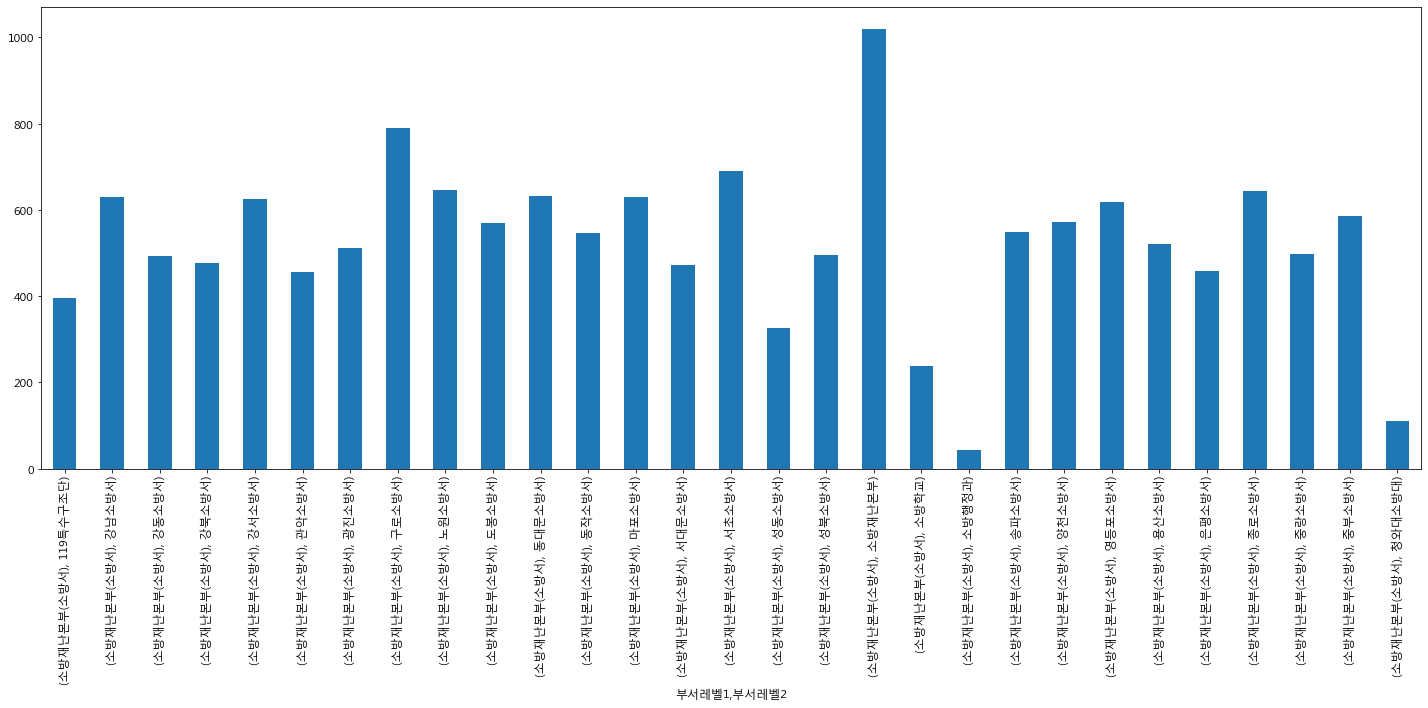
소방서에서는 소방재난본부에서 많은 비중을 나타내고 있었다.
부서레벨1 집행 총합
group_sum_1 = df_seoul_1[['부서레벨1', '부서레벨2', '집행금액']].groupby(['부서레벨1','부서레벨2'], as_index = True)['집행금액'].sum()
group_sum_1.plot(kind = 'bar')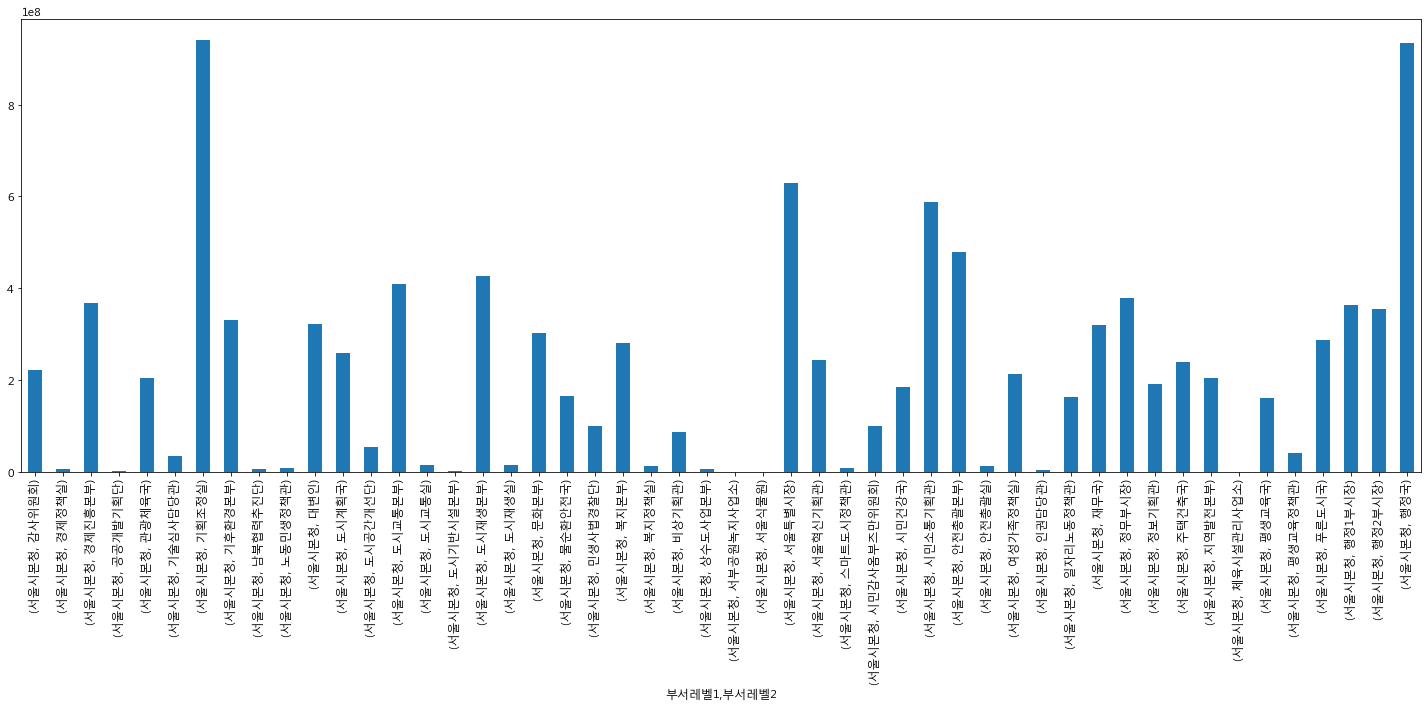
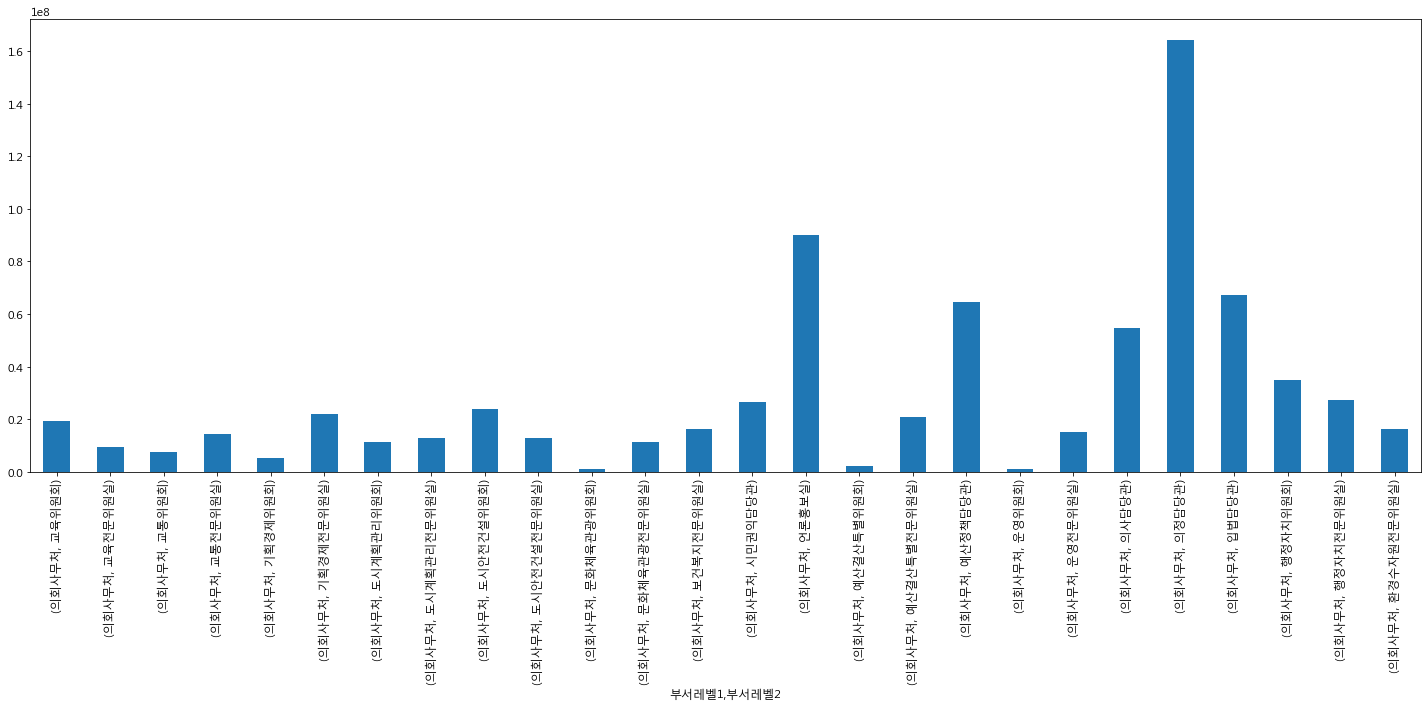
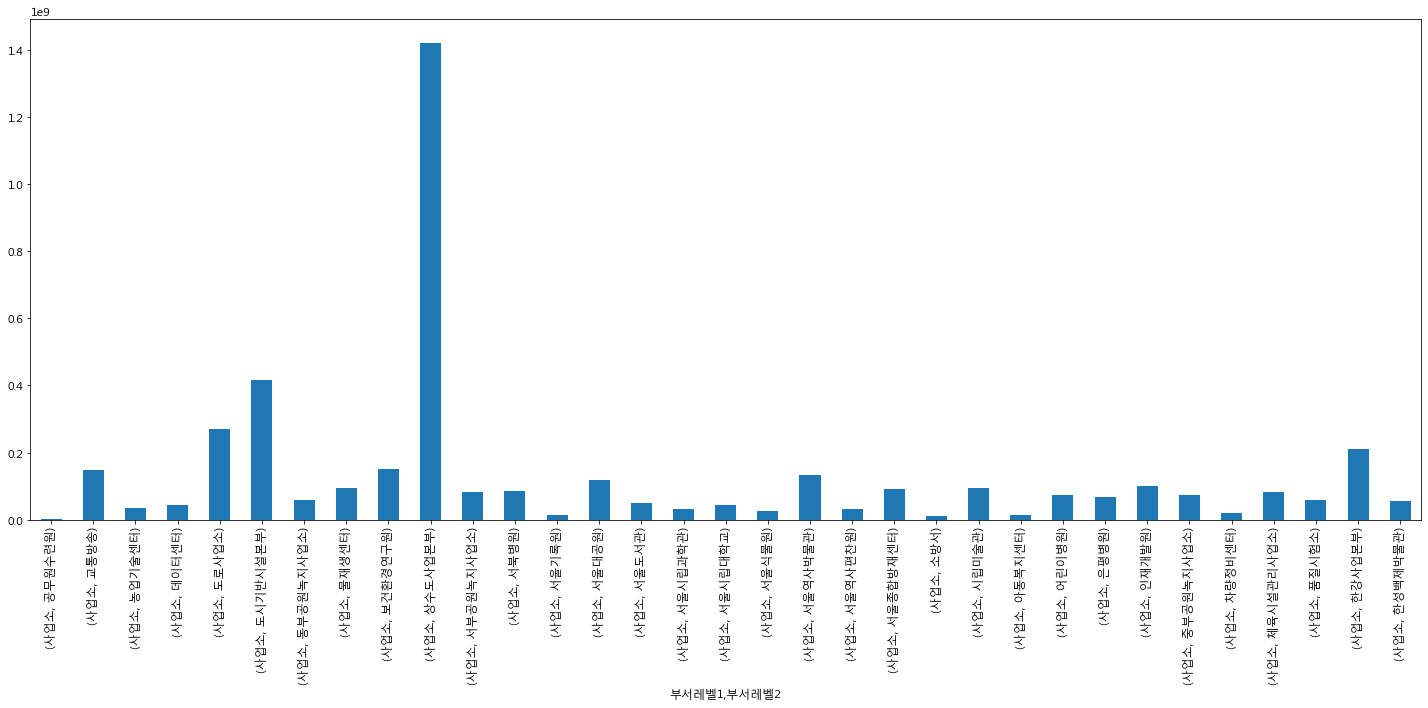
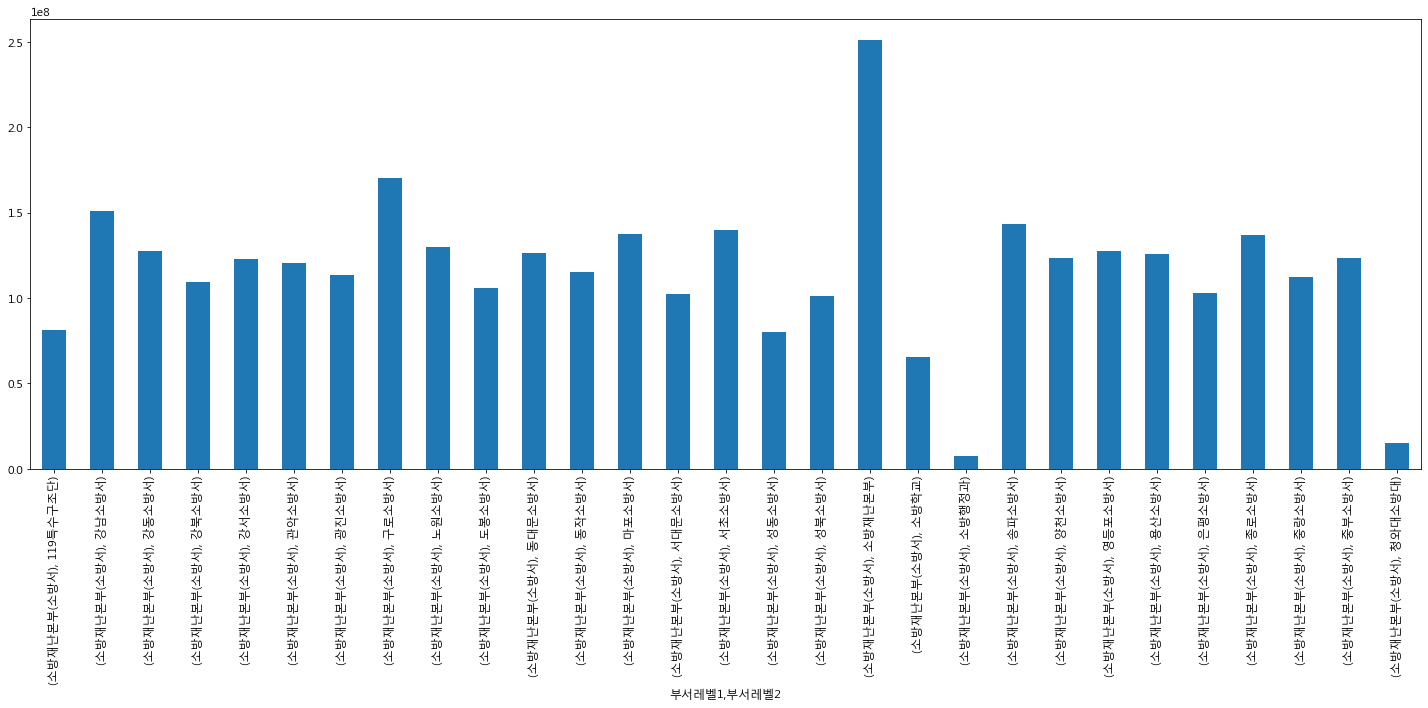
집행 건수와 금액은 그래프가 얼추 비슷해보인다. 상수도에 집중적으로 분석을 진행할 필요가 보인다. 기획조정실, 행정국에 초점을 두기로 했다.
연도별
year_expense = df_expense_all['집행연도'].value_counts()
year_expense
# 2018.0 72218
# 2017.0 70132
# Name: 집행연도, dtype: int642018년도가 조금 더 많다.
month_total = pd.pivot_table(df_expense_all, index = ['집행월'], values=['집행금액'],
aggfunc = sum)
year_month_total = pd.pivot_table(df_expense_all, index = ['집행월'], columns=['집행연도'],
values=['집행금액'], aggfunc = sum)
eok_won = 100000000 # 억원
(year_month_total/eok_won).plot.bar(rot=0)
plt.ylabel('집행금액(억원)')
plt.title("업무추진비의 월별 집행금액")
plt.legend(['2017년', '2018년'])
plt.show()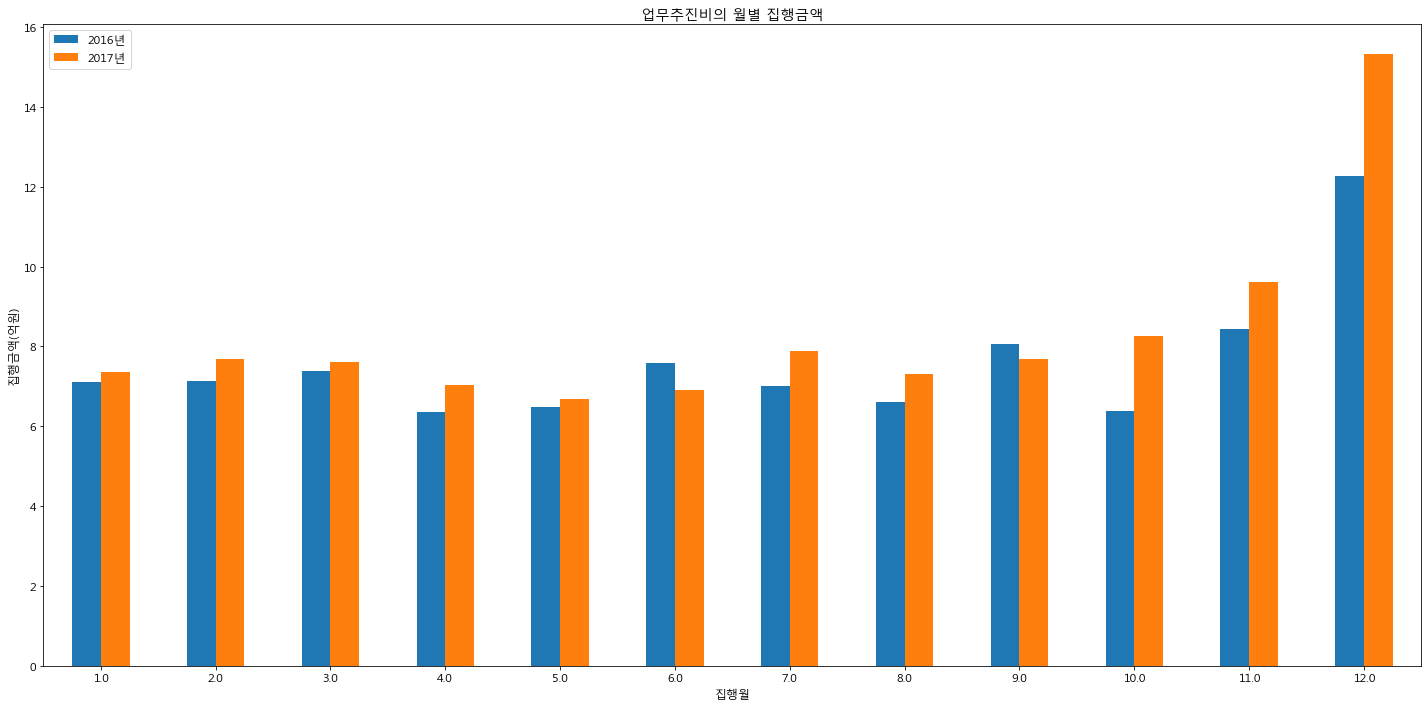
12월달에 가장 많은 집행금액이 발생한 것을 볼수가 있다. 10월부터는 점점 증가하는 추세가 보인다. 1~8월에는 그리 큰 변동이 있지 않아 보인다. 연도는 2017, 2018가 있다.
요일별 발생 건수 & 시간별 발생 건수
df_seoul['집행일시'].unique()
# array(['2017-01-26 13:10', '2017-01-25 22:41', '2017-01-24 12:35', ...,
# '2018-12-07 13:04', '2018-12-06 19:46', '2018-12-05 11:46'],
# dtype=object)집행일시컬럼을 보면 object로 되어 있다. 분석을 위해서는 datetime형식으로 변경을 해줘야한다.
# 날짜 -> 요일
week_day_name = ["월", "화", "수", "목", "금", "토", "일"]
df_seoul['집행일시_요일'] = [week_day_name[weekday] for weekday in expense_date_time.dt.weekday]
# 시간 변경
df_seoul['집행일시_시간'] = [hour for hour in expense_date_time.dt.hour]# 요일별 시각화
expense_weekday = expense_weekday.reindex(index = week_day_name)
expense_weekday.plot.bar(rot=0)
plt.title("요일별 업무추진비 집행 횟수")
plt.xlabel("요일")
plt.ylabel("집행 횟수")
plt.show()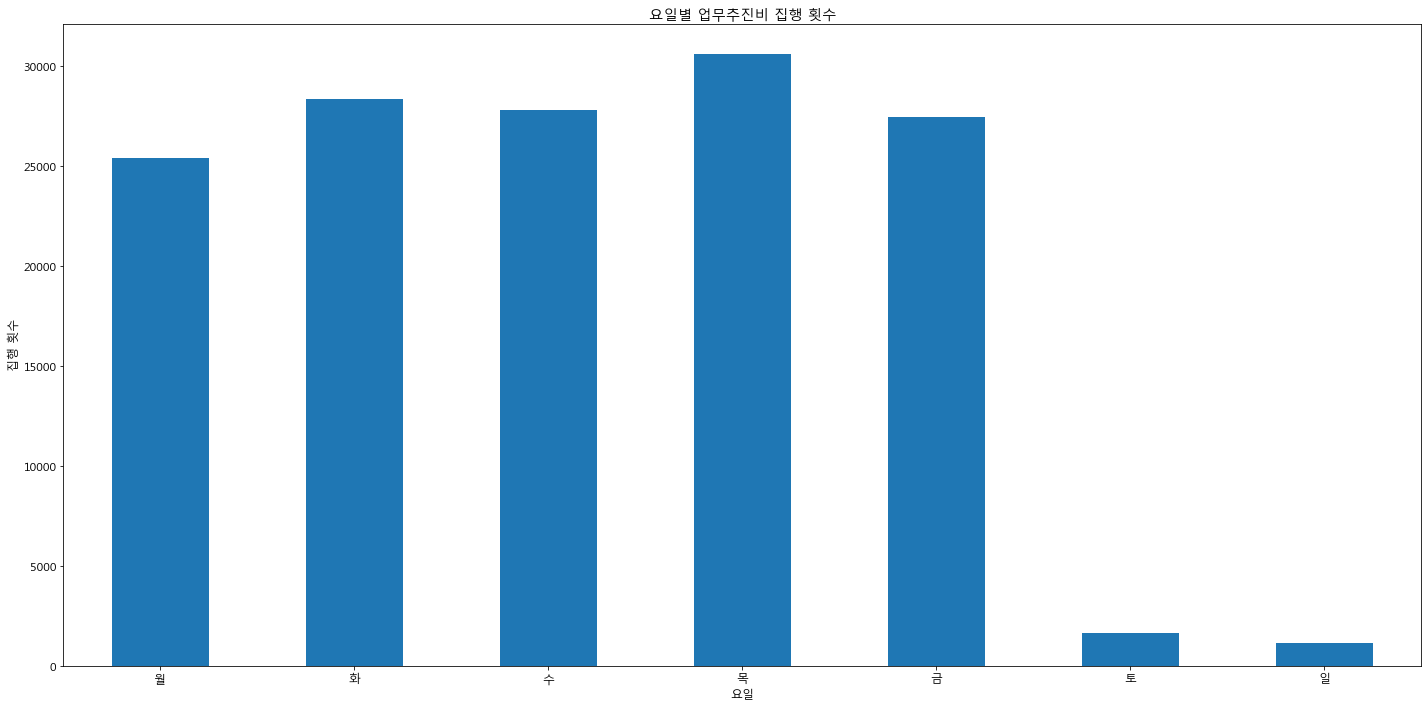
토, 일에도 발생을 한 것은 의외였다. 주말에 발생한 내역이 궁금하긴했다.
expense_hour_num = df_seoul['집행일시_시간'].value_counts()
work_hour = [ (k+8)%24 for k in range(24)]
expense_hour_num = expense_hour_num.reindex(index = work_hour)
expense_hour_num.plot.bar(rot = 0)
plt.title("시간별 업무추진비 집행 횟수")
plt.xlabel("집행 시간")
plt.ylabel("집행 횟수")
plt.show()
점심, 저녁시간때에 많이 발생한 것을 볼 수 가있다. 0시에도 이른 아침에도 발생한 건 의외였다. 다음은 상수도만 뽑아서 분석을 진행
'Python > 프로젝트' 카테고리의 다른 글
| Discord 미세먼지 Msg (0) | 2023.04.21 |
|---|---|
| 실전 데이터 분석 프로젝트(5) (0) | 2023.03.24 |
| 실전 데이터 분석 프로젝트(3) (0) | 2023.03.24 |
| 실전 데이터 분석 프로젝트(2) (0) | 2023.03.22 |
| 실전 데이터 분석 프로젝트(1) (0) | 2023.03.21 |
'Python/프로젝트' Related Articles
more



