
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 미세먼지
- MySQL
- 어쩌다 마케팅
- 파이썬 머신러닝 완벽가이드
- 중회귀모형
- 파이썬 철저 입문
- hackerrank
- 실전 데이터 분석 프로젝트
- 파이썬 머신러닝 완벽 가이드
- 프로그래머스
- 파이썬 철저입문
- 스파르타 코딩
- R
- 웹 스크랩핑
- 티스토리챌린지
- 내일배움캠프
- harkerrank
- Cluster
- TiL
- 프로젝트
- wil
- 오블완
- 내일배움
- 회귀분석
- SQL
- 텍스트 분석
- 스파르타코딩
- 내일배움카드
- 스파르타
- 파이썬
- Today
- Total
OkBublewrap
추천시스템 (3): 협업필터링 실습 본문
실습 자료
MovieLens 10M Dataset
MovieLens 10M movie ratings. Stable benchmark dataset. 10 million ratings and 100,000 tag applications applied to 10,000 movies by 72,000 users. Released 1/2009. README.txt ml-10m.zip (size: 63 MB,…
grouplens.org
환경 설정 - Colab
%%capture
!pip install numpy==1.26.4 --force-reinstall
print(np.__version__) # 1.26.4가 출력되어야 함
Colab에서 numpy 2.02으로 업데이트 되면서 surprise 패키지 호환성 문제가 생겼다.
그래서 numpy 다운그레이드를 하고 세션 다시 시작
사용자 영화 평점 데이터
import pandas as pd
import numpy as np
from google.colab import drive
drive.mount('/content/drive')
# 사용자 평점 데이터
ratings = pd.read_csv('ml-10M100K/ratings.dat'
, names=['user_id', 'movie_id', 'rating', 'timestamp']
, sep='::', encoding='latin-1', engine='python')
ratings.head(3)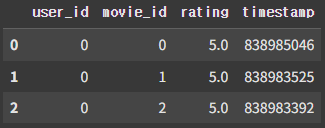
데이터 샘플링
# 데이터가 너무 많아서 일부만 사용함
print(ratings.shape)
# (10000054, 4)
mini_ratings = ratings.sample(frac=1, random_state=2025).iloc[:10000].reset_index(drop=True)
print(mini_ratings.shape)
# (10000, 4)
🚨 문제 생긴 패키지 다운 🚨
%%capture
!pip uninstall -y scikit-surprise
!pip install scikit-surprise --no-cache-dirimport pandas as pd
import numpy as np
from scipy.sparse.linalg import svds
from scipy.sparse import csr_matrix
from surprise import SVD, Dataset, Reader
from surprise.model_selection import train_test_split
from surprise import accuracy
SVD 직접 구현
- csr_matrix: 메모리 사용을 줄이고 연산을 최적화하기 위한 희소행렬 저장 방식
1️⃣ 사용자 - 아이템 평점 행렬 생성
user_movie_matrix = mini_ratings.pivot(index="user_id",
columns="movie_id", values="rating").fillna(0)
sparse_matrix = csr_matrix(user_movie_matrix)
2️⃣ SVD 구현
U, sigma, Vt = svds(sparse_matrix, k=50) # k=50은 잠재 요인의 개수
sigma = np.diag(sigma) # sigma를 대각 행렬로 변환
svds 는 Truncated SVD이고, 전체 행렬을 분해하는 것이 아니라, 상위 K 개의 가장 중요한 특이값만 선택하여 근사 행렬을 만든다.
3️⃣ 예측 평점 행렬 계산
predicted_ratings = np.dot(np.dot(U, sigma), Vt)
predicted_ratings_df = pd.DataFrame(predicted_ratings, index=user_movie_matrix.index, columns=user_movie_matrix.columns)
predicted_ratings_df.head(1)
예시)

Surprise 라이브러리를 활용한 SVD 행렬 분해
1️⃣ Surprise 데이터 객체 생성
# rating_scale: 평점 (1 ~ 5점) 설정
reader = Reader(rating_scale=(1, 5))
# 판다스 데이터프레임을 Surprise의 데이터셋 객체로 변환하는 함수
data = Dataset.load_from_df(mini_ratings[["user_id", "movie_id", "rating"]], reader)
2️⃣ 학습/테스트 데이터 분리
# 학습/테스트 데이터 분리
trainset, testset = train_test_split(data, test_size=0.2)
# SVD (ALS 기반) 모델 학습
model = SVD(n_factors=50, biased=True)
model.fit(trainset)
# 예측 및 RMSE 평가
predictions = model.test(testset)
rmse = accuracy.rmse(predictions)
print(f"🎯 Surprise SVD 모델의 RMSE: {rmse:.4f}")
# 🎯 Surprise SVD 모델의 RMSE: 1.0157
3️⃣ 예측 평점을 기반으로 영화 추천
# 특정 사용자에게 추천할 영화 선정
def get_movie_recommendations(user_id, n=10): # 10개 추천
movie_ids = ratings["movie_id"].unique() # (샘플링한) 전체 영화 리스트
watched_movies = ratings[ratings["user_id"] == user_id]["movie_id"].values # 사용자가 이미 본 영화 목록
# 사용자가 보지 않은 영화 리스트
unwatched_movies = [movie for movie in movie_ids if movie not in watched_movies]
# 각 영화에 대한 예측 평점 계산
predictions = [(movie, model.predict(user_id, movie).est) for movie in unwatched_movies]
# 예상 평점이 높은 상위 n개 영화 추천
top_movies = sorted(predictions, key=lambda x: x[1], reverse=True)[:n]
return top_movies
# 예시 실행
user_id = 1 # 추천받을 사용자
top_recommendations = get_movie_recommendations(user_id)
print(f"🎬 사용자 {user_id}에게 추천하는 영화:")
for movie_id, rating in top_recommendations:
print(f"영화 ID: {movie_id}, 예상 평점: {rating:.2f}")
🎬 사용자 1에게 추천하는 영화:
영화 ID: 2858, 예상 평점: 4.41
영화 ID: 50, 예상 평점: 4.40
영화 ID: 318, 예상 평점: 4.27
영화 ID: 260, 예상 평점: 4.26
영화 ID: 2571, 예상 평점: 4.23
영화 ID: 1204, 예상 평점: 4.22
영화 ID: 750, 예상 평점: 4.20
영화 ID: 527, 예상 평점: 4.19
영화 ID: 608, 예상 평점: 4.19
영화 ID: 2762, 예상 평점: 4.18
추가 정리 부분
# 각 영화에 대한 예측 평점 계산
predictions = [(movie, model.predict(user_id, movie).est) for movie in unwatched_movies]
# 예상 평점이 높은 상위 n개 영화 추천
top_movies = sorted(predictions, key=lambda x: x[1], reverse=True)[:n]
1. model.predict(user_id, movie_id)를 하면 출력 값은 아래와 같이 나온다.
Prediction(uid=1, iid=101, r_ui=None, est=4.72, details={'was_impossible': False})이중 est는 4.72 예측 평점을 산출한다. details 부분은 추가 정보로 예측이 불가능한 경우에는 was_impossible=True라고 나온다.
2. sorted(predictions, key=lambda x: x[1], reverse=True)[:n]
predictions = [
(101, 4.72), # 영화 ID 101의 예상 평점: 4.72
(203, 3.85), # 영화 ID 203의 예상 평점: 3.85
(345, 4.90), # 영화 ID 345의 예상 평점: 4.90
(567, 4.25), # 영화 ID 567의 예상 평점: 4.25
]
predictions이 이렇게 나온다면, (movie_id, expect_rating) 예상되는 평점을 가져와서 sorted 정렬을 한다 어떻게? reverse = True로 내림차순 정렬하고 함수 인자로 들어온 10개 [:10]으로 가져온다.
4️⃣ movie_id의 title 가져오기
# movies.dat 불러오기
movies = pd.read_csv("ml-10M100K/movies.dat", sep="::"
, engine="python", names=["movie_id", "title", "genres"])
# 영화 제목과 추천 결과 매칭
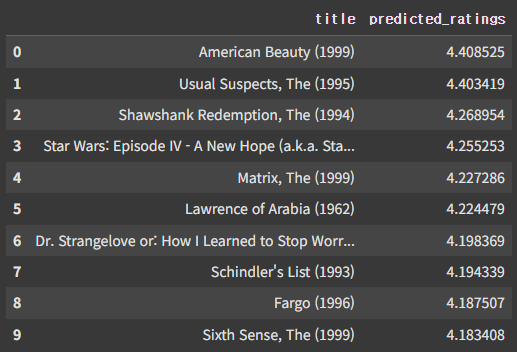
def get_movie_titles(movie_recommendations):
movie_df = pd.DataFrame(movie_recommendations, columns=["movie_id", "predicted_ratings"])
movie_df = movie_df.merge(movies, on="movie_id")
return movie_df[["title", "predicted_ratings"]]
# 영화 추천 결과 출력
recommendation_with_titles = get_movie_titles(top_recommendations)
user_id가 1인 영화 추천 목록
ALS를 이용한 행렬 분해
패키지 다운
%%capture
!pip install implicit
import implicit
1️⃣ userId와 movieId를 0부터 시작하는 인덱스로 변환
user_mapper = {id: i for i, id in enumerate(ratings["user_id"].unique())}
movie_mapper = {id: i for i, id in enumerate(ratings["movie_id"].unique())}
ratings["user_id"] = ratings["user_id"].map(user_mapper)
ratings["movie_id"] = ratings["movie_id"].map(movie_mapper)
- ALS 모델은 0부터 시작하는 연속된 인덱스를 사용해야 하므로 변환이 필요하다.
2️⃣ 희소 행렬 (CSR 형식) 생성
user_items = csr_matrix((
ratings["rating"],
(ratings["user_id"], ratings["movie_id"])
))
# 데이터 크기 확인
print(f"Users: {user_items.shape[0]}, Movies: {user_items.shape[1]}")
# Users: 69878, Movies: 10677
3️⃣ ALS 모델 생성
model = implicit.als.AlternatingLeastSquares(
factors=2, # 잠재 요인 개수 (Latent Factors)
regularization=0.1, # 정규화 파라미터 (Overfitting 방지)
iterations=20, # 학습 반복 횟수
use_gpu=False # GPU 사용 여부
)
4️⃣ 모델 훈련 (행렬을 전치하여 학습)
model.fit(user_items.T)- implicit 라이브러리의 ALS 모델은 기본적으로 아이템 기반 학습을 수행한다.
- 보통 사용자 기반으로 추천을 원하므로 전치하여 아이템-사용자 행렬로 변환
5️⃣ 특정 사용자에게 추천할 영화 예측
user_id = 0 # 예시 사용자 ID
recommendations = model.recommend(user_id, user_items[user_id], N=5)
print("추천 영화 (movieId, 예측 점수):", recommendations)
# 추천 영화 (movieId, 예측 점수): (array([50397, 29124, 15682, 35275, 65576], dtype=int32), array([0.39067173, 0.38358447, 0.37951487, 0.37548482, 0.3645503 ],
# dtype=float32))
'Python > 학습용' 카테고리의 다른 글
| 🐍 Python 파일 및 디렉터리 처리 완전 정복 (0) | 2025.04.12 |
|---|---|
| LLM - Fine-Tuning (0) | 2025.03.21 |
| 추천시스템 (2): 협업필터링 (0) | 2025.03.21 |
| LLM - RAG(2) (0) | 2025.03.20 |
| LLM - RAG(1) (0) | 2025.03.20 |